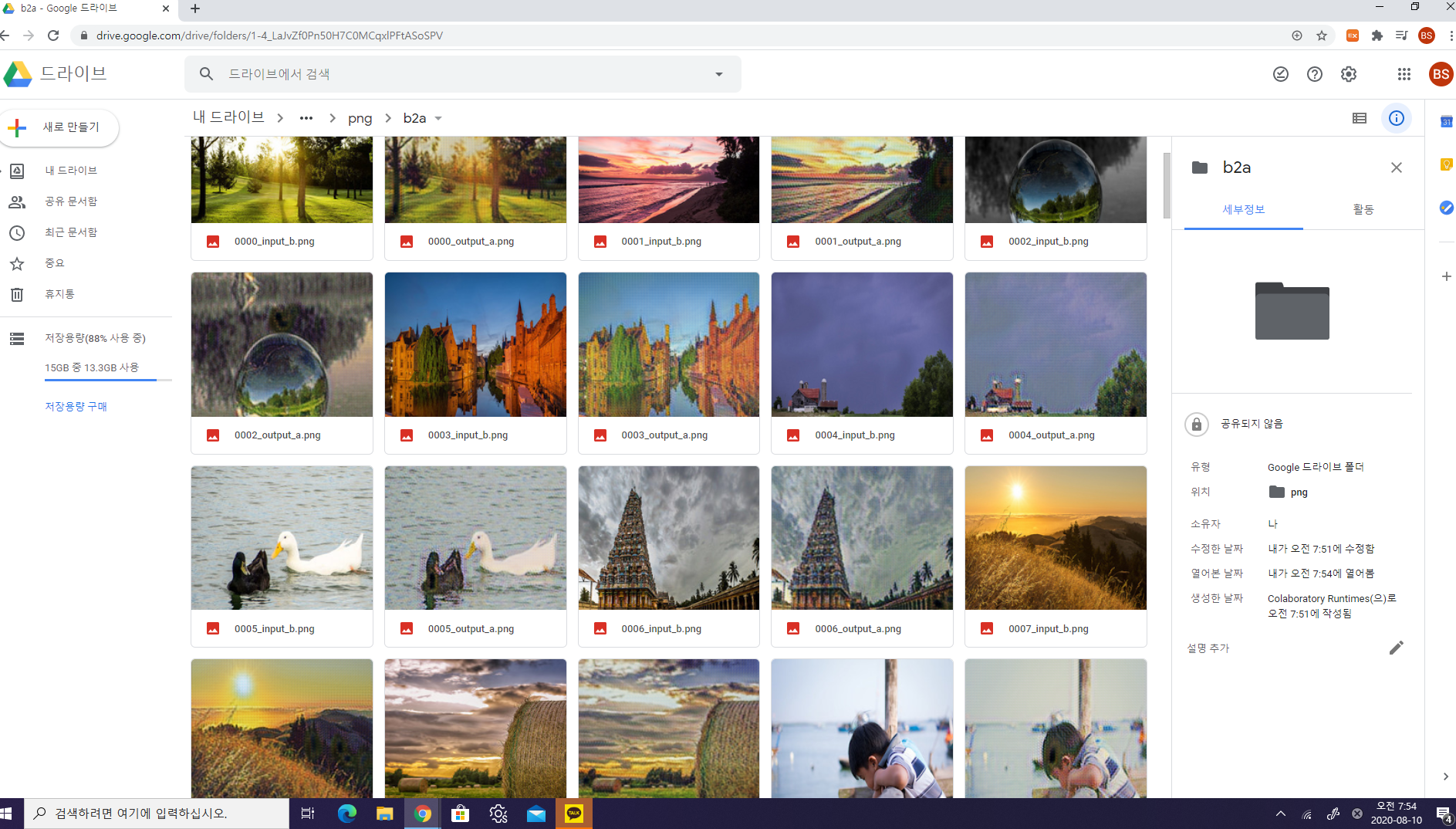
CYCLE GAN 구축
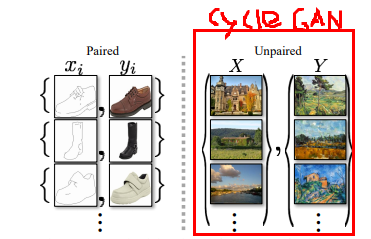
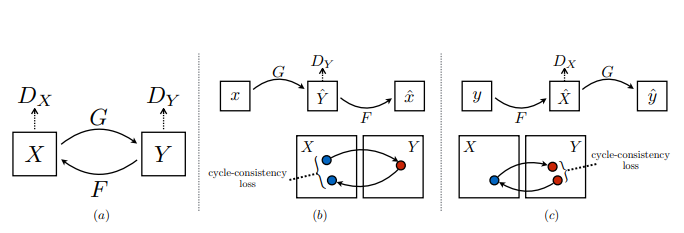
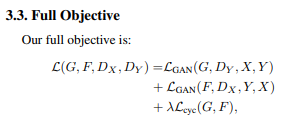

Model 추가하기
class DCGAN(nn.Module)
#model.py
class CycleGAN(nn.Module):
def __init__(self, in_channels, out_channels, nker=64, norm='bnorm', nblk=6):
super(DCGAN, self).__init__()
layer 추가하기
#layer.py
class CBR2d(nn.Module):
if padding_mode == 'reflection':
layers += [nn.ReflectionPad2d(padding)]
elif padding_mode == 'replication':
layers += [nn.ReplicationPad2d(padding)]
elif padding_mode == 'constant':
value = 0
layers += [nn.ConstantPad2d(padding, value)]
elif padding_mode == 'zeros':
layers += [nn.ZeroPad2d(padding)]
layers += [nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=0,
bias=bias)] # conv2d 에 적용된 padding 값을 0으로 변경
class DECBR2d(nn.Module):
layers += [nn.ConvTranspose2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding, output_padding=output_padding,
bias=bias)] # output_padding 추가
Model 추가하기
class CycleGAN(nn.Module)
class Discriminator(nn.Module)
#model.py
self.enc1 = CBR2d(self.in_channels, 1 * self.nker, kernel_size=7, stride=1, padding=3, norm=self.norm, relu=0.0) #c7s1-64 input channel = 64
self.enc2 = CBR2d(1 * self.nker, 2 * self.nker, kernel_size=3, stride=2, padding=1, norm=self.norm, relu=0.0) # d128
self.enc3 = CBR2d(2 * self.nker, 4 * self.nker, kernel_size=3, stride=2, padding=1, norm=self.norm, relu=0.0) # d256
if self.nblk:
res = []
# Residual Block
for i in range(self.nblk): # R256 * 9 => R256, R256, R256, R256, R256, R256, R256, R256, R256
res += [ResBlock(4 * self.nker, 4 * self.nker, kernel_size=3, stride=1, padding=1, norm=self.norm, relu=0.0)]
self.res = nn.Sequential(*res)
self.dec3 = DECBR2d(4 * self.nker, 2 * self.nker, kernel_size=3, stride=2, padding=1, norm=self.norm, relu=0.0) # u128 factional strided convolution 사용
self.dec2 = DECBR2d(2 * self.nker, 1 * self.nker, kernel_size=3, stride=2, padding=1, norm=self.norm, relu=0.0) # u64
self.dec1 = CBR2d(1 * self.nker, self.out_channels, kernel_size=7, stride=1, padding=3, norm=None, relu=None) # c7s1-3 output channel = 3
def forward(self, x):
x = self.enc1(x)
x = self.enc2(x)
x = self.enc3(x)
x = self.res(x)
x = self.dec3(x)
x = self.dec2(x)
x = self.dec1(x)
x = torch.tanh(x)
return x
main 수정하기
#main.py
# parameter paper와 맞추기
parser.add_argument("--lr", default=2e-4, type=float, dest="lr")
parser.add_argument("--batch_size", default=4, type=int, dest="batch_size")
parser.add_argument("--num_epoch", default=100, type=int, dest="num_epoch")
parser.add_argument("--task", default="cyclegan", choices=['cyclegan'], type=str, dest="task")
# cycle GAN에서는 2개의 weight 필요
parser.add_argument("--wgt_cycle", default=1e1, type=float, dest="wgt_cycle") # cycle consistency loss -> lambda = 10
parser.add_argument("--wgt_ident", default=5e-1, type=float, dest="wgt_ident") # identify mapping loss -> lambda = 0.5
parser.add_argument("--norm", default='inorm', type=str, dest="norm") # instance Normalization 사용
arg 수정하기
###
#train.py
wgt_cycle = args.wgt_cycle
wgt_ident = args.wgt_ident
## 네트워크 학습하기
dataset_train = Dataset(data_dir=os.path.join(data_dir, 'train'),
transform=transform_train,
task=task, data_type='both') # task, opts 제거후 data type = both
## 네트워크 생성하기
if network == "CycleGAN":
# Generator
netG_a2b = CycleGAN(in_channels=nch, out_channels=nch, nker=nker, norm=norm, nblk=9).to(device) # [G]
netG_b2a = CycleGAN(in_channels=nch, out_channels=nch, nker=nker, norm=norm, nblk=9).to(device) # Y -> X 로 transform 할 수 있는 Generator [F]
# Discriminator
netD_a = Discriminator(in_channels=nch, out_channels=1, nker=nker, norm=norm).to(device) # X domain에서 Real 과 Fake 구별 [Dx]
netD_b = Discriminator(in_channels=nch, out_channels=1, nker=nker, norm=norm).to(device) # Y domain에서 Real 과 Fake 구별 [Dy]
# weight init
init_weights(netG_a2b, init_type='normal', init_gain=0.02)
init_weights(netG_b2a, init_type='normal', init_gain=0.02)
init_weights(netD_a, init_type='normal', init_gain=0.02)
init_weights(netD_b, init_type='normal', init_gain=0.02)
## 손실함수 정의하기
fn_cycle = nn.L1Loss().to(device)
fn_gan = nn.BCELoss().to(device)
fn_ident = nn.L1Loss().to(device)
import itertools
## Optimizer 설정하기
optimG = torch.optim.Adam(itertools.chain(netG_a2b.parameters(), netG_b2a.parameters()), lr=lr, betas=(0.5, 0.999))
optimD = torch.optim.Adam(itertools.chain(netD_a.parameters(), netD_b.parameters()), lr=lr, betas=(0.5, 0.999))
load save하기
-
#
#util.py
## 네트워크 저장하기
def save(ckpt_dir, netG_a2b, netG_b2a, netD_a, netD_b, optimG, optimD, epoch):
if not os.path.exists(ckpt_dir):
os.makedirs(ckpt_dir)
torch.save({'netG_a2b': netG_a2b.state_dict(), 'netG_b2a': netG_b2a.state_dict(),
'netD_a': netD_a.state_dict(), 'netD_b': netD_b.state_dict(),
'optimG': optimG.state_dict(), 'optimD': optimD.state_dict()},
"%s/model_epoch%d.pth" % (ckpt_dir, epoch))
## 네트워크 불러오기
def load(ckpt_dir, netG_a2b, netG_b2a, netD_a, netD_b, optimG, optimD):
if not os.path.exists(ckpt_dir):
epoch = 0
return netG_a2b, netG_b2a, netD_a, netD_b, optimG, optimD, epoch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
ckpt_lst = os.listdir(ckpt_dir)
ckpt_lst = [f for f in ckpt_lst if f.endswith('pth')]
ckpt_lst.sort(key=lambda f: int(''.join(filter(str.isdigit, f))))
dict_model = torch.load('%s/%s' % (ckpt_dir, ckpt_lst[-1]), map_location=device)
netG_a2b.load_state_dict(dict_model['netG_a2b'])
netG_b2a.load_state_dict(dict_model['netG_b2a'])
netD_a.load_state_dict(dict_model['netD_a'])
netD_b.load_state_dict(dict_model['netD_b'])
optimG.load_state_dict(dict_model['optimG'])
optimD.load_state_dict(dict_model['optimD'])
epoch = int(ckpt_lst[-1].split('epoch')[1].split('.pth')[0])
return netG_a2b, netG_b2a, netD_a, netD_b, optimG, optimD, epoch
#train.py
## 네트워크 학습시키기
st_epoch = 0
# TRAIN MODE
if mode == 'train':
if train_continue == "on":
netG_a2b, netG_b2a, \
netD_a, netD_b, \
optimG, optimD, st_epoch = load(ckpt_dir=ckpt_dir,
netG_a2b=netG_a2b, netG_b2a=netG_b2a,
netD_a=netD_a, netD_b=netD_b,
optimG=optimG, optimD=optimD)
Train Loop 수정하기
-
#
#train.py
for epoch in range(st_epoch + 1, num_epoch + 1):
netG_a2b.train()
netG_b2a.train()
netD_a.train()
netD_b.train()
loss_G_a2b_train = []
loss_G_b2a_train = []
loss_D_a_train = []
loss_D_b_train = []
loss_cycle_a_train = []
loss_cycle_b_train = []
loss_ident_a_train = []
loss_ident_b_train = []
# DATA LOADER 수정
#dataset.py
## 데이터 로더를 구현하기
class Dataset(torch.utils.data.Dataset):
def __init__(self, data_dir, transform=None, task=None, data_type='both'): # task, opts 삭제 후 data type추가
self.data_dir_a = data_dir + 'A' # 각각의 dir로 split해서 저장
self.data_dir_b = data_dir + 'B' # 각각의 dir로 split해서 저장
self.transform = transform
self.task = task
self.data_type = data_type
# Updated at Apr 5 2020
self.to_tensor = ToTensor()
# dir_A와 dir_B 나누어서 호출
if os.path.exists(self.data_dir_a):
lst_data_a = os.listdir(self.data_dir_a)
lst_data_a = [f for f in lst_data_a if f.endswith('jpg') | f.endswith('jpeg') | f.endswith('png')]
lst_data_a.sort()
else:
lst_data_a = []
# dir_A와 dir_B 나누어서 호출
if os.path.exists(self.data_dir_b):
lst_data_b = os.listdir(self.data_dir_b)
lst_data_b = [f for f in lst_data_b if f.endswith('jpg') | f.endswith('jpeg') | f.endswith('png')]
lst_data_b.sort()
else:
lst_data_b = []
self.lst_data_a = lst_data_a
self.lst_data_b = lst_data_b
# TrainA, TrainB의 length가 다르기 때문에 둘 중에 짧은 쪽에 맞추어서 생성
def __len__(self):
if self.data_type == 'both':
if len(self.lst_data_a) < len(self.lst_data_b):
return len(self.lst_data_a)
else:
return len(self.lst_data_b)
elif self.data_type == 'a':
return len(self.lst_data_a)
elif self.data_type == 'b':
return len(self.lst_data_b)
# Data TYPE에 맞게 getitem 수정
def __getitem__(self, index):
data = {}
# dataset A 호출
if self.data_type == 'a' or self.data_type == 'both':
data_a = plt.imread(os.path.join(self.data_dir_a, self.lst_data_a[index]))[:, :, :3]
if data_a.ndim == 2:
data_a = data_a[:, :, np.newaxis]
if data_a.dtype == np.uint8:
data_a = data_a / 255.0
# data = {'data_a': data_a}
data['data_a'] = data_a
# dataset B 호출
if self.data_type == 'b' or self.data_type == 'both':
data_b = plt.imread(os.path.join(self.data_dir_b, self.lst_data_b[index]))[:, :, :3]
if data_b.ndim == 2:
data_b = data_b[:, :, np.newaxis]
if data_b.dtype == np.uint8:
data_b = data_b / 255.0
# data = {'data_b': data_b}
data['data_b'] = data_b
if self.transform:
data = self.transform(data)
data = self.to_tensor(data)
return data
class RandomCrop(object):
def __init__(self, shape):
self.shape = shape
def __call__(self, data):
# 이제는 key value를 label값으로 가져왔지만 이제는 dataA, dataB 어떤것이 올지 알수 없으므로 받아서 사용하게끔 수정
# input, label = data['input'], data['label']
# h, w = input.shape[:2]
keys = list(data.keys())
h, w = data[keys[0]].shape[:2]
new_h, new_w = self.shape
top = np.random.randint(0, h - new_h)
left = np.random.randint(0, w - new_w)
id_y = np.arange(top, top + new_h, 1)[:, np.newaxis]
id_x = np.arange(left, left + new_w, 1)
# input = input[id_y, id_x]
# label = label[id_y, id_x]
# data = {'label': label, 'input': input}
# Updated at Apr 5 2020
for key, value in data.items():
data[key] = value[id_y, id_x]
return data
# train.py
for batch, data in enumerate(loader_train, 1):
input_a = data['data_a'].to(device)
input_b = data['data_b'].to(device)
# forward netG
output_b = netG_a2b(input_a) # X -> Y translation
output_a = netG_b2a(input_b) # output_b가 network F를 통과해서 input domain X로 돌아옴
recon_b = netG_a2b(output_a)
recon_a = netG_b2a(output_b)
# Discriminator update
# backward netD
set_requires_grad([netD_a, netD_b], True)
optimD.zero_grad()
# backward netD_a
pred_real_a = netD_a(input_a) # input_a를 real a로 prediction
pred_fake_a = netD_a(output_a.detach()) # output_a를 fake a로 prediction
loss_D_a_real = fn_gan(pred_real_a, torch.ones_like(pred_real_a)) # prediction된 variable을 GAN loass로 구현
loss_D_a_fake = fn_gan(pred_fake_a, torch.zeros_like(pred_fake_a))
loss_D_a = 0.5 * (loss_D_a_real + loss_D_a_fake) # loss를 더해서 final Discriminator a 의 loss로 정의
# backward netD_b
pred_real_b = netD_b(input_b)
pred_fake_b = netD_b(output_b.detach())
loss_D_b_real = fn_gan(pred_real_b, torch.ones_like(pred_real_b))
loss_D_b_fake = fn_gan(pred_fake_b, torch.zeros_like(pred_fake_b))
loss_D_b = 0.5 * (loss_D_b_real + loss_D_b_fake) # loss를 더해서 final Discriminator b 의 loss로 정의
# 최종 Discriminator의 loss 정의
loss_D = loss_D_a + loss_D_b
loss_D.backward()
optimD.step()
# backward netG
set_requires_grad([netD_a, netD_b], False)
optimG.zero_grad()
pred_fake_a = netD_a(output_a)
pred_fake_b = netD_b(output_b)
loss_G_a2b = fn_gan(pred_fake_a, torch.ones_like(pred_fake_a)) # prediction된 pred_fake_ar값이 Discriminator를 속이기 위해 ones_like로 mapping
loss_G_b2a = fn_gan(pred_fake_b, torch.ones_like(pred_fake_b))
loss_cycle_a = fn_cycle(input_a, recon_a) # 생성된 이미지와 input 이미지 간의 cycle consistency loss
loss_cycle_b = fn_cycle(input_b, recon_b)
ident_a = netG_b2a(input_a) # [G= from x to y] input_a에서 a가 나올수 잇게끔 정리
ident_b = netG_a2b(input_b) # [G= from x to y] input_b에서 b가 나올수 잇게끔 정리
loss_ident_a = fn_ident(input_a, ident_a) # target domain의 input이 network의 output으로 나올 수 있게끔 정리
loss_ident_b = fn_ident(input_b, ident_b)
loss_G = (loss_G_a2b + loss_G_b2a) + \
wgt_cycle * (loss_cycle_a + loss_cycle_b) + \
wgt_cycle * wgt_ident * (loss_ident_a + loss_ident_b)
# (loss_G_a2b + loss_G_b2a) = adversarial loss
# wgt_cycle * (loss_cycle_a + loss_cycle_b) = cycle consistency loss
# wgt_cycle * wgt_ident * (loss_ident_a + loss_ident_b) = identified mapping
loss_G.backward()
optimG.step()
# 손실함수 계산
loss_G_a2b_train += [loss_G_a2b.item()]
loss_G_b2a_train += [loss_G_b2a.item()]
loss_D_a_train += [loss_D_a.item()]
loss_D_b_train += [loss_D_b.item()]
loss_cycle_a_train += [loss_cycle_a.item()]
loss_cycle_b_train += [loss_cycle_b.item()]
loss_ident_a_train += [loss_ident_a.item()]
loss_ident_b_train += [loss_ident_b.item()]
print("TRAIN: EPOCH %04d / %04d | BATCH %04d / %04d | "
"GEN a2b %.4f b2a %.4f | "
"DISC a %.4f b %.4f | "
"CYCLE a %.4f b %.4f | "
"IDENT a %.4f b %.4f | " %
(epoch, num_epoch, batch, num_batch_train,
np.mean(loss_G_a2b_train), np.mean(loss_G_b2a_train),
np.mean(loss_D_a_train), np.mean(loss_D_b_train),
np.mean(loss_cycle_a_train), np.mean(loss_cycle_b_train),
np.mean(loss_ident_a_train), np.mean(loss_ident_b_train)))
if batch % 20 == 0:
# Tensorboard 저장하기 이미지 저장
input_a = fn_tonumpy(fn_denorm(input_a)).squeeze()
input_b = fn_tonumpy(fn_denorm(input_b)).squeeze()
output_a = fn_tonumpy(fn_denorm(output_a)).squeeze()
output_b = fn_tonumpy(fn_denorm(output_b)).squeeze()
input_a = np.clip(input_a, a_min=0, a_max=1)
input_b = np.clip(input_b, a_min=0, a_max=1)
output_a = np.clip(output_a, a_min=0, a_max=1)
output_b = np.clip(output_b, a_min=0, a_max=1)
id = num_batch_train * (epoch - 1) + batch
plt.imsave(os.path.join(result_dir_train, 'png', 'a2b', '%04d_input_a.png' % id), input_a[0],
cmap=cmap)
plt.imsave(os.path.join(result_dir_train, 'png', 'a2b', '%04d_output_b.png' % id), output_b[0],
cmap=cmap)
plt.imsave(os.path.join(result_dir_train, 'png', 'b2a', '%04d_input_b.png' % id), input_b[0],
cmap=cmap)
plt.imsave(os.path.join(result_dir_train, 'png', 'b2a', '%04d_output_a.png' % id), output_a[0],
cmap=cmap)
writer_train.add_image('input_a', input_a, id, dataformats='NHWC')
writer_train.add_image('input_b', input_b, id, dataformats='NHWC')
writer_train.add_image('output_a', output_a, id, dataformats='NHWC')
writer_train.add_image('output_b', output_b, id, dataformats='NHWC')
writer_train.add_scalar('loss_G_a2b', np.mean(loss_G_a2b_train), epoch)
writer_train.add_scalar('loss_G_b2a', np.mean(loss_G_b2a_train), epoch)
writer_train.add_scalar('loss_D_a', np.mean(loss_D_a_train), epoch)
writer_train.add_scalar('loss_D_b', np.mean(loss_D_b_train), epoch)
writer_train.add_scalar('loss_cycle_a', np.mean(loss_cycle_a_train), epoch)
writer_train.add_scalar('loss_cycle_b', np.mean(loss_cycle_b_train), epoch)
writer_train.add_scalar('loss_ident_a', np.mean(loss_ident_a_train), epoch)
writer_train.add_scalar('loss_ident_b', np.mean(loss_ident_b_train), epoch)
# 네트워크 저장
if epoch % 2 == 0 or epoch == num_epoch:
save(ckpt_dir=ckpt_dir, epoch=epoch,
netG_a2b=netG_a2b, netG_b2a=netG_b2a,
netD_a=netD_a, netD_b=netD_b,
optimG=optimG, optimD=optimD)
writer_train.close()
test 하기
-
#
#train.py
wgt_cycle = args.wgt_cycle
wgt_ident = args.wgt_ident
## 네트워크 학습하기
if mode == 'test':
# DATA LOADER
transform_test = transforms.Compose([Resize(shape=(ny, nx, nch)), Normalization(mean=MEAN, std=STD)])
# dataset 따로 호출
dataset_test_a = Dataset(data_dir=os.path.join(data_dir, 'test'), transform=transform_test, task=task,
data_type='a')
loader_test_a = DataLoader(dataset_test_a, batch_size=batch_size, shuffle=False, num_workers=NUM_WORKER)
# 그밖에 부수적인 variables 설정하기
num_data_test_a = len(dataset_test_a)
num_batch_test_a = np.ceil(num_data_test_a / batch_size)
# dataset 따로 호출
dataset_test_b = Dataset(data_dir=os.path.join(data_dir, 'test'), transform=transform_test, task=task,
data_type='b')
loader_test_b = DataLoader(dataset_test_b, batch_size=batch_size, shuffle=False, num_workers=NUM_WORKER)
# 그밖에 부수적인 variables 설정하기
num_data_test_b = len(dataset_test_b)
num_batch_test_b = np.ceil(num_data_test_b / batch_size)
## 네트워크 생성하기
if network == "CycleGAN":
netG_a2b = CycleGAN(in_channels=nch, out_channels=nch, nker=nker, norm=norm, nblk=9).to(device)
netG_b2a = CycleGAN(in_channels=nch, out_channels=nch, nker=nker, norm=norm, nblk=9).to(device)
netD_a = Discriminator(in_channels=nch, out_channels=1, nker=nker, norm=norm).to(device)
netD_b = Discriminator(in_channels=nch, out_channels=1, nker=nker, norm=norm).to(device)
init_weights(netG_a2b, init_type='normal', init_gain=0.02)
init_weights(netG_b2a, init_type='normal', init_gain=0.02)
init_weights(netD_a, init_type='normal', init_gain=0.02)
init_weights(netD_b, init_type='normal', init_gain=0.02)
## 손실함수 정의하기
fn_cycle = nn.L1Loss().to(device)
fn_gan = nn.BCELoss().to(device)
fn_ident = nn.L1Loss().to(device)
## Optimizer 설정하기
optimG = torch.optim.Adam(itertools.chain(netG_a2b.parameters(), netG_b2a.parameters()), lr=lr, betas=(0.5, 0.999))
optimD = torch.optim.Adam(itertools.chain(netD_a.parameters(), netD_b.parameters()), lr=lr, betas=(0.5, 0.999))
## 네트워크 학습시키기
st_epoch = 0
# TRAIN MODE
if mode == "test":
netG_a2b, netG_b2a, \
netD_a, netD_b, \
optimG, optimD, st_epoch = load(ckpt_dir=ckpt_dir,
netG_a2b=netG_a2b, netG_b2a=netG_b2a,
netD_a=netD_a, netD_b=netD_b,
optimG=optimG, optimD=optimD)
with torch.no_grad():
# Test에는 Generator만 있으면 되므로 Generator만 Evaluation
netG_a2b.eval()
netG_b2a.eval()
# testset A
for batch, data in enumerate(loader_test_a, 1):
# forward pass
input_a = data['data_a'].to(device)
output_b = netG_a2b(input_a)
# Tensorboard 저장하기
input_a = fn_tonumpy(fn_denorm(input_a))
output_b = fn_tonumpy(fn_denorm(output_b))
for j in range(input_a.shape[0]):
id = batch_size * (batch - 1) + j
input_a_ = input_a[j]
output_b_ = output_b[j]
input_a_ = np.clip(input_a_, a_min=0, a_max=1)
output_b_ = np.clip(output_b_, a_min=0, a_max=1)
plt.imsave(os.path.join(result_dir_test, 'png', 'a2b', '%04d_input_a.png' % id), input_a_)
plt.imsave(os.path.join(result_dir_test, 'png', 'a2b', '%04d_output_b.png' % id), output_b_)
print("TEST A: BATCH %04d / %04d | " % (id + 1, num_data_test_a))
# testset B
for batch, data in enumerate(loader_test_b, 1):
# forward pass
input_b = data['data_b'].to(device)
output_a = netG_b2a(input_b)
# Tensorboard 저장하기
input_b = fn_tonumpy(fn_denorm(input_b))
output_a = fn_tonumpy(fn_denorm(output_a))
for j in range(input_b.shape[0]):
id = batch_size * (batch - 1) + j
input_b_ = input_b[j]
output_a_ = output_a[j]
input_b_ = np.clip(input_b_, a_min=0, a_max=1)
output_a_ = np.clip(output_a_, a_min=0, a_max=1)
plt.imsave(os.path.join(result_dir_test, 'png', 'b2a', '%04d_input_b.png' % id), input_b_)
plt.imsave(os.path.join(result_dir_test, 'png', 'b2a', '%04d_output_a.png' % id), output_a_)
print("TEST B: BATCH %04d / %04d | " % (id + 1, num_data_test_b))
image -> photo
photo -> image