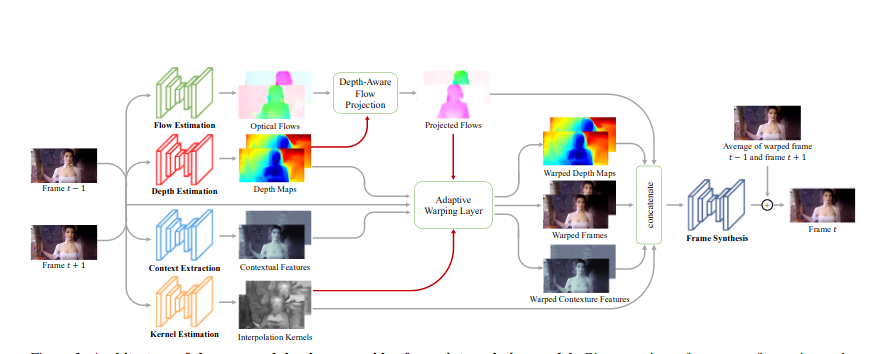
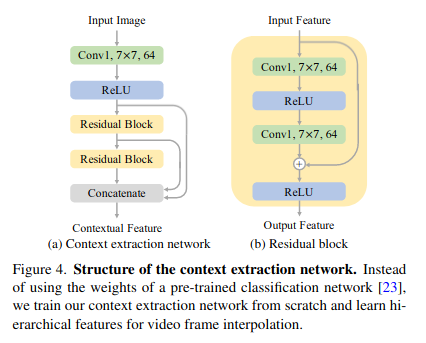
DAIN 사용
GIT에서 LOCAL로 code 내려받기
PAKAGE import
!pip install -r requirements.txt
PARAMETER 설정
INPUT_FILEPATH = "/content/DAIN/samples/input.gif"
OUTPUT_FILE_PATH = "/content/DAIN/samples/output.mp4"
TARGET_FPS = 60
FRAME_INPUT_DIR = '/content/DAIN/input_frames' # frame 으로 분해
FRAME_OUTPUT_DIR = '/content/DAIN/output_frames' #frame 으로 분해
START_FRAME = 1
END_FRAME = -1
SEAMLESS = False # 영상의 처음과 끝을 이을 지 확인
RESIZE_HOTFIX = True
AUTO_REMOVE = False
REBUILD_CUDA_EXTENSIONS = False # 쿠다 확장프로그램
GPU 환경 및 ubuntu, python 환경 설정
!nvidia-smi --query-gpu=gpu_name,driver_version,memory.total --format=csv # GPU
!pip install torch==1.4.0+cu100 torchvision==0.5.0+cu100 -f \
https://download.pytorch.org/whl/torch_stable.html # cuda 및 pytorch 환경
!pip install scipy==1.1.0
!sudo apt-get install imagemagick imagemagick-doc libx264. # 코덱설치
print("Finished installing dependencies.")
## CUDA 환경 설치
if (REBUILD_CUDA_EXTENSIONS):
# This takes a while. Just wait. ~15 minutes.
# Building DAIN.
%cd /content/DAIN/my_package/
!./build.sh
print("Building #1 done.")
# Wait again. ~5 minutes.
# Building DAIN PyTorch correlation package.
%cd /content/DAIN/PWCNet/correlation_package_pytorch1_0
!./build.sh
print("Building #2 done.")
else:
%set_env PYTHONPATH=/content/DAIN/Colab:/content/DAIN:/env/python
!python -m easy_install /content/DAIN/Colab/*.egg
pretrain 된 Model 다운받기
#model.py
%cd /content/DAIN/Colab
!mkdir model_weights
!wget -O model_weights/best.pth http://vllab1.ucmerced.edu/~wenbobao/DAIN/best.pth
Video를 image로 변환
## yolov4
%shell rm -rf '{FRAME_INPUT_DIR}'
%shell mkdir -p '{FRAME_INPUT_DIR}'
if (END_FRAME==-1):
%shell ffmpeg -i '{INPUT_FILEPATH}' -vf 'select=gte(n\,{START_FRAME}),setpts=PTS-STARTPTS' '{FRAME_INPUT_DIR}/%05d.png'
else:
%shell ffmpeg -i '{INPUT_FILEPATH}' -vf 'select=between(n\,{START_FRAME}\,{END_FRAME}),setpts=PTS-STARTPTS' '{FRAME_INPUT_DIR}/%05d.png'
from IPython.display import clear_output
clear_output()
png_generated_count_command_result = %shell ls '{FRAME_INPUT_DIR}' | wc -l
frame_count = int(png_generated_count_command_result.output.strip())
import shutil
if SEAMLESS:
frame_count += 1
first_frame = f"{FRAME_INPUT_DIR}/00001.png"
new_last_frame = f"{FRAME_INPUT_DIR}/{frame_count.zfill(5)}.png"
shutil.copyfile(first_frame, new_last_frame)
Image의 Alpha 채널 (각 화소에 대해 색상 표현의 데이터로부터 분리한 보조 데이터를) 삭제
import subprocess as sp
%cd {FRAME_INPUT_DIR}
channels = sp.getoutput('identify -format %[channels] 00001.png')
print (f"{channels} detected")
# Removing alpha if detected
if "a" in channels:
print("Alpha channel detected and will be removed.")
print(sp.getoutput('find . -name "*.png" -exec convert "{}" -alpha off PNG24:"{}" \;'))
예측
%cd /content/DAIN/Colab
%shell mkdir -p '{FRAME_OUTPUT_DIR}'
!python -W ignore colab_interpolate.py --netName DAIN_slowmotion --time_step \
{fps/ TARGET_FPS} --start_frame 1 --end_frame {frame_count} --frame_input_dir \
'{FRAME_INPUT_DIR}' --frame_output_dir '{FRAME_OUTPUT_DIR}'
resize hotfix 및 img -> Video
%cd {FRAME_OUTPUT_DIR}
if (RESIZE_HOTFIX):
images = []
for filename in os.listdir(FRAME_OUTPUT_DIR):
img = cv2.imread(os.path.join(FRAME_OUTPUT_DIR, filename))
filename = os.path.splitext(filename)[0]
if(not filename.endswith('0')):
dimensions = (img.shape[1]+2, img.shape[0]+2)
resized = cv2.resize(img, dimensions, interpolation=cv2.INTER_LANCZOS4)
crop = resized[1:(dimensions[1]-1), 1:(dimensions[0]-1)]
cv2.imwrite(f"{filename}.png", crop)
# img -> Video
%shell ffmpeg -pattern_type glob -i '{FRAME_OUTPUT_DIR}/*.png' -y -r \
{TARGET_FPS} -c:v libx264 -pix_fmt yuv420p '{OUTPUT_FILE_PATH}'
# -c:v libx264 264 코덱 사용

