DCGAN 구축
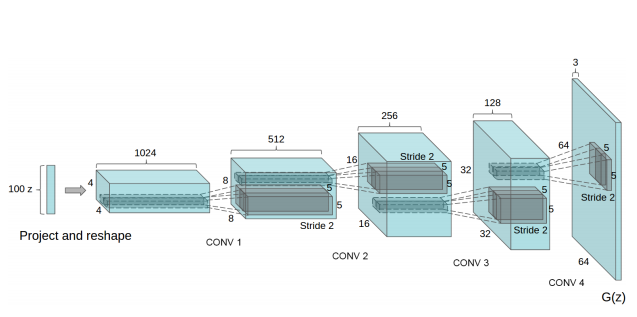
Model 추가하기
class DCGAN(nn.Module)
#model.py
class DCGAN(nn.Module):
def __init__(self, in_channels, out_channels, nker=64, norm="bnorm"):
super(DCGAN, self).__init__()
layer 추가하기
class DECBR2d(nn.Module)
#layer.py
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=True, norm="bnorm", relu=0.0):
super().__init__()
layers = []
layers += [nn.ConvTranspose2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding,
bias=bias)] # ConvTranspose2d를 사용 Discriminator가 stride에 비례하여 증가하기 떄문
if not norm is None:
if norm == "bnorm":
layers += [nn.BatchNorm2d(num_features=out_channels)]
elif norm == "inorm":
layers += [nn.InstanceNorm2d(num_features=out_channels)]
if not relu is None and relu >= 0.0:
layers += [nn.ReLU() if relu == 0 else nn.LeakyReLU(relu)]
self.cbr = nn.Sequential(*layers)
def forward(self, x):
return self.cbr(x)
Model 추가하기
class DCGAN(nn.Module)
class Discriminator(nn.Module)
# Generator : input(100,1,1) --> output(3, 64, 64)
# DECBR2d ConvTranspose2d 사용. Dimension이 stride에 비례하여 증가
#model.py
self.dec1 = DECBR2d(1 * in_channels, 8 * nker, kernel_size=4, stride=1,
padding=0, norm=norm, relu=0.0, bias=False) # 정보량 변동이 없기 때문에 그대로 사용
self.dec2 = DECBR2d(8 * nker, 4 * nker, kernel_size=4, stride=2,
padding=1, norm=norm, relu=0.0, bias=False) # 2. 1024 -> 512 = 4 * nker // Stride는 모델에서 제시한 2를 사용
self.dec3 = DECBR2d(4 * nker, 2 * nker, kernel_size=4, stride=2,
padding=1, norm=norm, relu=0.0, bias=False)
self.dec4 = DECBR2d(2 * nker, 1 * nker, kernel_size=4, stride=2,
padding=1, norm=norm, relu=0.0, bias=False)
self.dec5 = DECBR2d(1 * nker, out_channels, kernel_size=4, stride=2,
padding=1, norm=None, relu=None, bias=False) # 논문에서 norm과 relu 사용하지 않고 Tanh를 사용하라고 지정.
def forward(self, x):
x = self.dec1(x)
x = self.dec2(x)
x = self.dec3(x)
x = self.dec4(x)
x = self.dec5(x)
x = torch.tanh(x) # 논문에서 마지막 layer엔 Tanh를 사용하라고 지정.
return x
# Discriminator: Input(3, 64, 64) --> output(1,1,1) Generatior와 는 반대로 진행
# Image를 입력 받은 Discriminator의 출력값
# 1) 출력값 >= 0.5 : Real Image로 판단
# 2) 출력값 < 0.5 : Fake Image로 판단(Generator로 만들어진 Image)
# CBR2d Conv2d 사용. Dimension이 stride에 반비례하여 감소하기 떄문
class Discriminator(nn.Module):
def __init__(self, in_channels, out_channels, nker=64, norm="bnorm"):
super(Discriminator, self).__init__()
self.enc1 = CBR2d(1 * in_channels, 1 * nker, kernel_size=4, stride=2,
padding=1, norm=norm, relu=0.2, bias=False)
self.enc2 = CBR2d(1 * nker, 2 * nker, kernel_size=4, stride=2,
padding=1, norm=norm, relu=0.2, bias=False)
self.enc3 = CBR2d(2 * nker, 4 * nker, kernel_size=4, stride=2,
padding=1, norm=norm, relu=0.2, bias=False)
self.enc4 = CBR2d(4 * nker, 8 * nker, kernel_size=4, stride=2,
padding=1, norm=norm, relu=0.2, bias=False)
self.enc5 = CBR2d(8 * nker, out_channels, kernel_size=4, stride=2,
padding=1, norm=None, relu=None, bias=False)
def forward(self, x):
x = self.enc1(x)
x = self.enc2(x)
x = self.enc3(x)
x = self.enc4(x)
x = self.enc5(x)
x = torch.sigmoid(x) # 논문에 따라서 마지막 layer 의 output이 sigmoid로 나오게끔 함
return x
network 추가하기
DCGAN은 Generator와 Discriminator의 총 2개의 네트워크가 필요함
#train.py
# DCGAN 추가
if network == "DCGAN":
netG = DCGAN(in_channels=100, out_channels=nch, nker=nker).to(device)
netD = Discriminator(in_channels=nch, out_channels=1, nker=nker).to(device) # scala 값으로 되기 때문에 out_channels = 1
init_weights(netG, init_type='normal', init_gain=0.02)
init_weights(netD, init_type='normal', init_gain=0.02)
network 초기화하는 함수 만들기
def init_weights(net, init_type=’normal’, init_gain=0.02)
# Initial routine 추가(normal, xavier, kaiming, orthogonal)
#util.py
def init_weights(net, init_type='normal', init_gain=0.02):
def init_func(m): # define the initialization function
classname = m.__class__.__name__
if hasattr(m, 'weight') and (classname.find('Conv') != -1 or classname.find('Linear') != -1):
if init_type == 'normal':
nn.init.normal_(m.weight.data, 0.0, init_gain)
elif init_type == 'xavier':
nn.init.xavier_normal_(m.weight.data, gain=init_gain)
elif init_type == 'kaiming':
nn.init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
elif init_type == 'orthogonal':
nn.init.orthogonal_(m.weight.data, gain=init_gain)
else:
raise NotImplementedError('initialization method [%s] is not implemented' % init_type)
if hasattr(m, 'bias') and m.bias is not None:
nn.init.constant_(m.bias.data, 0.0)
elif classname.find('BatchNorm2d') != -1: # BatchNorm Layer's weight is not a matrix; only normal distribution applies.
nn.init.normal_(m.weight.data, 1.0, init_gain)
nn.init.constant_(m.bias.data, 0.0)
print('initialize network with %s' % init_type)
net.apply(init_func) # apply the initialization function <init_func>
loss 함수 정의하기
-
# GAN 모델이 Gernerator와 Discriminator가 서로 경쟁하며 최대가 되게끔 하는데 사용하는 함수 BinaryCrossEntrophy를 사용
#train.py
fn_loss = nn.BCELoss().to(device)
Optimizer 설정하기
-
# GAN 모델이 Gernerator와 Discriminator 2개의 네트워크를 사용하므로 optimizer 도 각각 설정
#train.py
optimG = torch.optim.Adam(netG.parameters(), lr=lr, betas=(0.5, 0.999)) # momentum term β 값을 default 값인 0.9가 아닌 0.5를 사용.
optimD = torch.optim.Adam(netD.parameters(), lr=lr, betas=(0.5, 0.999)) # 0.9를 사용하면 train cerve가 oscillation 하거나 instability 하기때문
save와 load 설정하기
def save(ckpt_dir, netG, netD, optimG, optimD, epoch)
def load(ckpt_dir, netG, netD, optimG, optimD)
# GAN 모델이 Gernerator와 Discriminator 2개의 네트워크를 사용하므로 save, load 도 각각 설정
#util.py
def save(ckpt_dir, netG, netD, optimG, optimD, epoch):
if not os.path.exists(ckpt_dir):
os.makedirs(ckpt_dir)
torch.save({'netG': netG.state_dict(), 'netD': netD.state_dict(),
'optimG': optimG.state_dict(), 'optimD': optimD.state_dict()},
"%s/model_epoch%d.pth" % (ckpt_dir, epoch))
def load(ckpt_dir, netG, netD, optimG, optimD):
if not os.path.exists(ckpt_dir):
epoch = 0
return netG, netD, optimG, optimD, epoch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
ckpt_lst = os.listdir(ckpt_dir)
ckpt_lst.sort(key=lambda f: int(''.join(filter(str.isdigit, f))))
dict_model = torch.load('%s/%s' % (ckpt_dir, ckpt_lst[-1]), map_location=device)
netG.load_state_dict(dict_model['netG'])
netD.load_state_dict(dict_model['netD'])
optimG.load_state_dict(dict_model['optimG'])
optimD.load_state_dict(dict_model['optimD'])
epoch = int(ckpt_lst[-1].split('epoch')[1].split('.pth')[0])
return netG, netD, optimG, optimD, epoch
save와 load 설정하기
###
# GAN 모델이 Gernerator와 Discriminator 2개의 네트워크를 사용하므로 save, load 도 각각 설정
#train.py
# TRAIN MODE
if mode == 'train':
if train_continue == "on":
netG, netD, optimG, optimD, st_epoch = load(ckpt_dir=ckpt_dir,
netG=netG, netD=netD,
optimG=optimG, optimD=optimD)
train loop 수정
###
# GAN 모델이 Gernerator와 Discriminator 2개의 네트워크를 사용하므로 save, load 도 각각 설정
#train.py
for epoch in range(st_epoch + 1, num_epoch + 1):
netG.train()
netD.train()
loss_G_train = []
loss_D_real_train = [] # original image의 loss
loss_D_fake_train = [] # Generatior가 생성한 Fake image의 loss
for batch, data in enumerate(loader_train, 1):
# forward pass
label = data['label'].to(device)
input = torch.randn(label.shape[0], 100, 1, 1,).to(device) #(B, C, H, W) // x= 1, y = 1, ch =100 를 가진 noise 생성
output = netG(input)
역전파 추가
def set_requires_grad(nets, requires_grad=False)
# 네트워크의 para에 대하여 grad를 계산할지 말지 정하는 함수
#util.py
def set_requires_grad(nets, requires_grad=False):
"""Set requies_grad=Fasle for all the networks to avoid unnecessary computations
Parameters:
nets (network list) -- a list of networks
requires_grad (bool) -- whether the networks require gradients or not
"""
if not isinstance(nets, list):
nets = [nets]
for net in nets:
if net is not None:
for param in net.parameters():
param.requires_grad = requires_grad
역전파 추가
-
# Discriminator에 역전파 추가
#train.py
# backward netD
set_requires_grad(netD, True) # require가 True 이기 떄문에 Discriminator의 para가 update 수행
optimD.zero_grad()
pred_real = netD(label) # label이라는 original을 넣으면 pred 은 True를 갖기를 원하게 됨
pred_fake = netD(output.detach()) # generator의 output을 넣으면 pred 은 False를 갖기를 원하게 됨
# .detach()로 Discriminator의 backward routine이 Generator로 넘어가지 않도록 연결을 끊어줌
loss_D_real = fn_loss(pred_real, torch.ones_like(pred_real)) # ones_like = True
loss_D_fake = fn_loss(pred_fake, torch.zeros_like(pred_fake)) # zeros_like = False
loss_D = 0.5 * (loss_D_real + loss_D_fake)
loss_D.backward()
optimD.step()
# backward netG
set_requires_grad(netD, False)
optimG.zero_grad()
pred_fake = netD(output) # original value 그대로 사용
loss_G = fn_loss(pred_fake, torch.ones_like(pred_fake)) # 가짜를 진짜처럼 인식하도록 하기위해 ones_line(fake)를 사용
loss_G.backward()
optimG.step()
손실함수 추가
-
# Generator의 손실함수, Discriminator의 real의 손실함수, Discriminator의 fake의 손실함수
#train.py
# 손실함수 계산
loss_G_train += [loss_G.item()]
loss_D_real_train += [loss_D_real.item()]
loss_D_fake_train += [loss_D_fake.item()]
print("TRAIN: EPOCH %04d / %04d | BATCH %04d / %04d | "
"GEN %.4f | DISC REAL: %.4f | DISC FAKE: %.4f" %
(epoch, num_epoch, batch, num_batch_train,
np.mean(loss_G_train), np.mean(loss_D_real_train), np.mean(loss_D_fake_train)))
학습시키기
-
#
#train.py
if batch % 20 == 0:
# Tensorboard 저장하기
# 모델에서 Tanh를 사용해서 1~-1 사이로 Normalization을 하였기 때문에 denormaization을 사용해서 0~1로 transform 시킴
output = fn_tonumpy(fn_denorm(output, mean=0.5, std=0.5)).squeeze()
output = np.clip(output, a_min=0, a_max=1)
id = num_batch_train * (epoch - 1) + batch
plt.imsave(os.path.join(result_dir_train, 'png', '%04d_output.png' % id), output[0].squeeze(), cmap=cmap)
writer_train.add_image('output', output, id, dataformats='NHWC')
writer_train.add_scalar('loss_G', np.mean(loss_G_train), epoch)
writer_train.add_scalar('loss_D_real', np.mean(loss_D_real_train), epoch)
writer_train.add_scalar('loss_D_fake', np.mean(loss_D_fake_train), epoch)
if epoch % 2 == 0 or epoch == num_epoch:
save(ckpt_dir=ckpt_dir, netG=netG, netD=netD, optimG=optimG, optimD=optimD, epoch=epoch) # network save도 수정
test 하기
-
#
#train.py
if mode == "test":
netG, netD, optimG, optimD, st_epoch = load(ckpt_dir=ckpt_dir, netG=netG, netD=netD, optimG=optimG, optimD=optimD)
with torch.no_grad():
netG.eval()
input = torch.randn(batch_size, 100, 1, 1).to(device) # Generator는 noise로 이미지를 생성하면 되므로 바로 이미지 생성, 갯수는 batch_size에 의해서 결정
output = netG(input)
output = fn_tonumpy(fn_denorm(output, mean=0.5, std=0.5))
for j in range(output.shape[0]):
id = j
output_ = output[j]
np.save(os.path.join(result_dir_test, 'numpy', '%04d_output.npy' % id), output_)
output_ = np.clip(output_, a_min=0, a_max=1)
plt.imsave(os.path.join(result_dir_test, 'png', '%04d_output.png' % id), output_, cmap=cmap)
CelebA Dataset 다운
class Resize(object):
# Image Size가 모델의 요구사항 64x64에 맞지 않으므로 이미지를 resize를 하도록 함.
#dataset.py
class Resize(object):
def __init__(self, shape):
self.shape = shape
def __call__(self, data):
for key, value in data.items():
data[key] = resize(value, output_shape=(self.shape[0], self.shape[1],
self.shape[2]))
return data
#train.py
if mode == 'train':
transform_train = transforms.Compose([Resize(shape=(ny, nx, nch)), Normalization(mean=0.5, std=0.5)]) # Normalization를 사용해서 -1~ 1사이로 수정
dataset_train = Dataset(data_dir=data_dir, transform=transform_train, task=task, opts=opts)
loader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True, num_workers=8)
# 그밖에 부수적인 variables 설정하기
num_data_train = len(dataset_train)
num_batch_train = np.ceil(num_data_train / batch_size)
main 정의
-
# arg를 main으로 옮김
#main.py
## Parser 생성하기
parser = argparse.ArgumentParser(description="Regression Tasks such as inpainting, denoising, and super_resolution",
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument("--mode", default="train", choices=["train", "test"], type=str, dest="mode")
parser.add_argument("--train_continue", default="on", choices=["on", "off"], type=str, dest="train_continue")
parser.add_argument("--lr", default=2e-4, type=float, dest="lr")
parser.add_argument("--batch_size", default=128, type=int, dest="batch_size")
parser.add_argument("--num_epoch", default=5, type=int, dest="num_epoch")
# parser.add_argument("--data_dir", default="./../datasets/img_align_celeba", type=str, dest="data_dir")
parser.add_argument("--data_dir", default="./../../datasets/img_align_celeba", type=str, dest="data_dir")
parser.add_argument("--ckpt_dir", default="./checkpoint", type=str, dest="ckpt_dir")
parser.add_argument("--log_dir", default="./log", type=str, dest="log_dir")
parser.add_argument("--result_dir", default="./result", type=str, dest="result_dir")
parser.add_argument("--task", default="DCGAN", choices=['DCGAN'], type=str, dest="task")
parser.add_argument('--opts', nargs='+', default=['bilinear', 4.0, 0], dest='opts')
parser.add_argument("--ny", default=64, type=int, dest="ny")
parser.add_argument("--nx", default=64, type=int, dest="nx")
parser.add_argument("--nch", default=3, type=int, dest="nch")
parser.add_argument("--nker", default=128, type=int, dest="nker")
parser.add_argument("--network", default="DCGAN", choices=["DCGAN"], type=str, dest="network")
parser.add_argument("--learning_type", default="plain", choices=["plain", "residual"], type=str, dest="learning_type")
args = parser.parse_args()
if __name__ == "__main__":
if args.mode == "train":
train(args)
elif args.mode == "test":
test(args)
