Pix2Pix 구축
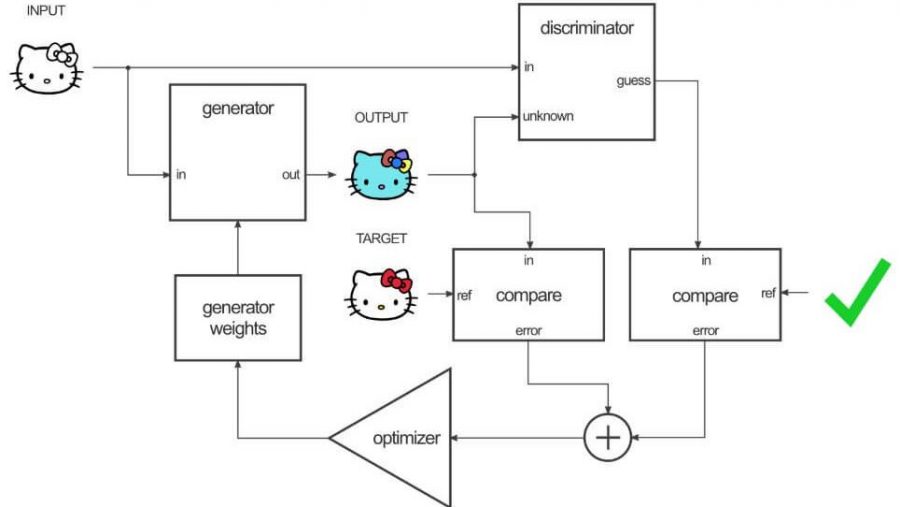
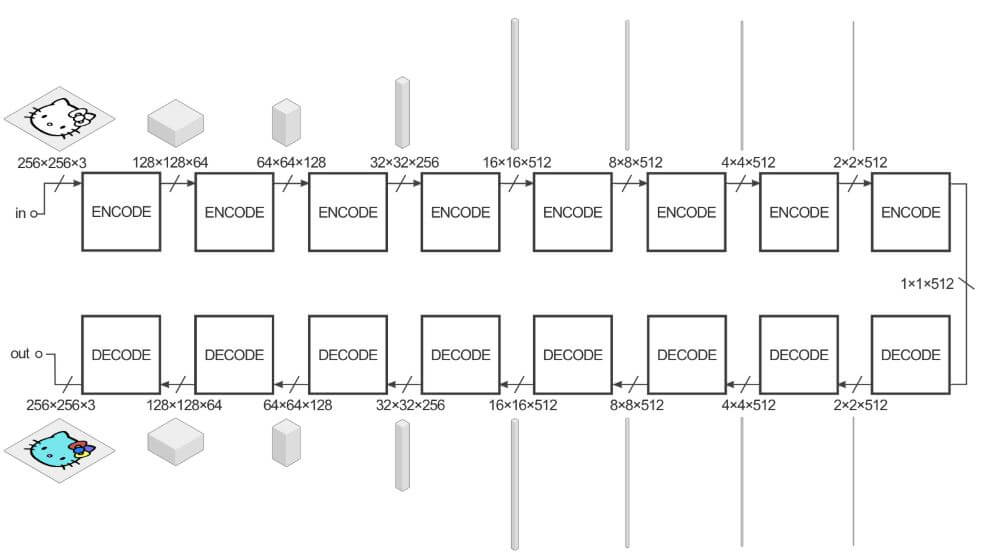
Generator
Discriminator

Model 추가하기
class Pix2Pix(nn.Module)
#model.py
class Pix2Pix(nn.Module):
def __init__(self, in_channels, out_channels, nker=64, norm="bnorm"):
super(Pix2Pix, self).__init__()
Model 추가하기
class Pix2Pix(nn.Module)
class Discriminator(nn.Module)
#model.py
# Encoder
# Downsampling factor가 2인 conv layer가 정의되어 있기 때문에 CBR2d 사용.
self.enc1 = CBR2d(in_channels, 1 * nker, kernel_size=4, padding=1,
norm=None, relu=0.2, stride=2)
self.enc2 = CBR2d(1 * nker, 2 * nker, kernel_size=4, padding=1,
norm=norm, relu=0.2, stride=2) # 2번째 layer 부터는 batch Norm사용.
self.enc3 = CBR2d(2 * nker, 4 * nker, kernel_size=4, padding=1,
norm=norm, relu=0.2, stride=2)
self.enc4 = CBR2d(4 * nker, 8 * nker, kernel_size=4, padding=1,
norm=norm, relu=0.2, stride=2)
self.enc5 = CBR2d(8 * nker, 8 * nker, kernel_size=4, padding=1,
norm=norm, relu=0.2, stride=2) # channel 512로 고정되어있기 때문에 아래부터는 동일한 값 사용
self.enc6 = CBR2d(8 * nker, 8 * nker, kernel_size=4, padding=1,
norm=norm, relu=0.2, stride=2)
self.enc7 = CBR2d(8 * nker, 8 * nker, kernel_size=4, padding=1,
norm=norm, relu=0.2, stride=2)
self.enc8 = CBR2d(8 * nker, 8 * nker, kernel_size=4, padding=1,
norm=norm, relu=0.2, stride=2)
# Decoder
# Upsampling factor가 2인 conv layer가 정의되어 있기 때문에 DECBR2d 사용.
# CD = Channel + Dropout
self.dec1 = DECBR2d(8 * nker, 8 * nker, kernel_size=4, padding=1,
norm=norm, relu=0.0, stride=2) # original relu 사용
self.drop1 = nn.Dropout2d(0.5) # dropout 적용
self.dec2 = DECBR2d(2 * 8 * nker, 8 * nker, kernel_size=4, padding=1,
norm=norm, relu=0.0, stride=2) # Channel 1024 이므로 이전보다 2배를 해줌
self.drop2 = nn.Dropout2d(0.5)
self.dec3 = DECBR2d(2 * 8 * nker, 8 * nker, kernel_size=4, padding=1,
norm=norm, relu=0.0, stride=2)
self.drop3 = nn.Dropout2d(0.5)
self.dec4 = DECBR2d(2 * 8 * nker, 8 * nker, kernel_size=4, padding=1,
norm=norm, relu=0.0, stride=2)
self.dec5 = DECBR2d(2 * 8 * nker, 4 * nker, kernel_size=4, padding=1,
norm=norm, relu=0.0, stride=2)
self.dec6 = DECBR2d(2 * 4 * nker, 2 * nker, kernel_size=4, padding=1,
norm=norm, relu=0.0, stride=2)
self.dec7 = DECBR2d(2 * 2 * nker, 1 * nker, kernel_size=4, padding=1,
norm=norm, relu=0.0, stride=2)
self.dec8 = DECBR2d(2 * 1 * nker, out_channels, kernel_size=4, padding=1,
norm=None, relu=None, stride=2)
# forward
def forward(self, x):
enc1 = self.enc1(x)
enc2 = self.enc2(enc1)
enc3 = self.enc3(enc2)
enc4 = self.enc4(enc3)
enc5 = self.enc5(enc4)
enc6 = self.enc6(enc5)
enc7 = self.enc7(enc6)
enc8 = self.enc8(enc7)
dec1 = self.dec1(enc8)
drop1 = self.drop1(dec1)
cat2 = torch.cat((drop1, enc7), dim=1) # dropout 된 data와 Encoder와 concat // Decorder의 채널이 Concat 덕분에 2배가 됨(1024)
dec2 = self.dec2(cat2)
drop2 = self.drop2(dec2)
cat3 = torch.cat((drop2, enc6), dim=1)
dec3 = self.dec3(cat3)
drop3 = self.drop3(dec3)
cat4 = torch.cat((drop3, enc5), dim=1)
dec4 = self.dec4(cat4)
cat5 = torch.cat((dec4, enc4), dim=1)
dec5 = self.dec5(cat5)
cat6 = torch.cat((dec5, enc3), dim=1)
dec6 = self.dec6(cat6)
cat7 = torch.cat((dec6, enc2), dim=1)
dec7 = self.dec7(cat7)
cat8 = torch.cat((dec7, enc1), dim=1)
dec8 = self.dec8(cat8)
x = torch.tanh(dec8)
return x
network 추가하기
#main.py
# pix2pix 추가
parser.add_argument("--task", default="pix2pix", choices=['DCGAN', 'pix2pix'], type=str, dest="task")
parser.add_argument("--num_epoch", default=300, type=int, dest="num_epoch")
parser.add_argument("--batch_size", default=10, type=int, dest="batch_size")
# direction 0 : input(right) => label(left)
# direction 1 : label(left) => input(right)
parser.add_argument('--opts', nargs='+', default=['direction', 0], dest='opts')
parser.add_argument("--nker", default=64, type=int, dest="nker") # 커널 사이즈 64
# L1 lamda parameter 정의
parser.add_argument("--wgt", default=1e2, type=float, dest="wgt")
network 추가하기
#train.py
# pix2pix 추가
wgt = args.wgt # parser로 추가한 wgt 받아오기
## 디렉토리 생성하기
result_dir_train = os.path.join(result_dir, 'train')
result_dir_val = os.path.join(result_dir, 'val')
if not os.path.exists(result_dir_train):
os.makedirs(os.path.join(result_dir_train, 'png'))
if not os.path.exists(result_dir_val):
os.makedirs(os.path.join(result_dir_val, 'png'))
## Data Loader 추가하기
## Random jitter 구현을 위해 Resize shape 을 286, 286으로 정의하고 RandomCrop을 추가
if mode == 'train':
transform_train = transforms.Compose([Resize(shape=(286, 286, nch)),
RandomCrop((ny, nx)),
Normalization(mean=0.5, std=0.5)])
dataset 수정
def getitem(self, index)
# Derection에 따라 Data Label과 Input으로 나누어주는 작업 추가
#dataset.py
if self.opts[0] == 'direction':
if self.opts[1] == 0: # label: left | input: right
data = {'label': img[:, :sz[1]//2, :], 'input': img[:, sz[1]//2:, :]}
elif self.opts[1] == 1: # label: right | input: left
data = {'label': img[:, sz[1]//2:, :], 'input': img[:, :sz[1]//2, :]}
else:
data = {'label': img}
network 추가하기
#train.py
# pix2pix 추가
elif network == "pix2pix":
netG = Pix2Pix(in_channels=nch, out_channels=nch, nker=nker, norm=norm).to(device)
# pix2pix에서 사용되는 Discriminator는 Conditional GAN을 사용하기 때문에
# input과 output이 concat 된 이미지가 discriminator의 input으로 전달
# 따라서 channel size를 2배로 늘려야함
netD = Discriminator(in_channels=2 * nch, out_channels=1, nker=nker, norm=norm).to(device)
init_weights(netG, init_type='normal', init_gain=0.02)
init_weights(netD, init_type='normal', init_gain=0.02)
loss 함수 정의하기
GAN loss와 L1 loss 사용
# GAN 모델이 Gernerator와 Discriminator가 서로 경쟁하며 최대가 되게끔 하는데 사용하는 함수 BinaryCrossEntrophy를 사용
#train.py
fn_l1 = nn.L1Loss().to(device)
fn_gan = nn.BCELoss().to(device)
Optimizer 설정하기
-
# GAN 모델이 Gernerator와 Discriminator 2개의 네트워크를 사용하므로 optimizer 도 각각 설정
#train.py
optimG = torch.optim.Adam(netG.parameters(), lr=lr, betas=(0.5, 0.999)) # momentum term β 값을 default 값인 0.9가 아닌 0.5를 사용.
optimD = torch.optim.Adam(netD.parameters(), lr=lr, betas=(0.5, 0.999)) # 0.9를 사용하면 train cerve가 oscillation 하거나 instability 하기때문
save와 load 설정하기
def save(ckpt_dir, netG, netD, optimG, optimD, epoch)
def load(ckpt_dir, netG, netD, optimG, optimD)
# GAN 모델이 Gernerator와 Discriminator 2개의 네트워크를 사용하므로 save, load 도 각각 설정
#util.py
def save(ckpt_dir, netG, netD, optimG, optimD, epoch):
if not os.path.exists(ckpt_dir):
os.makedirs(ckpt_dir)
torch.save({'netG': netG.state_dict(), 'netD': netD.state_dict(),
'optimG': optimG.state_dict(), 'optimD': optimD.state_dict()},
"%s/model_epoch%d.pth" % (ckpt_dir, epoch))
def load(ckpt_dir, netG, netD, optimG, optimD):
if not os.path.exists(ckpt_dir):
epoch = 0
return netG, netD, optimG, optimD, epoch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
ckpt_lst = os.listdir(ckpt_dir)
ckpt_lst.sort(key=lambda f: int(''.join(filter(str.isdigit, f))))
dict_model = torch.load('%s/%s' % (ckpt_dir, ckpt_lst[-1]), map_location=device)
netG.load_state_dict(dict_model['netG'])
netD.load_state_dict(dict_model['netD'])
optimG.load_state_dict(dict_model['optimG'])
optimD.load_state_dict(dict_model['optimD'])
epoch = int(ckpt_lst[-1].split('epoch')[1].split('.pth')[0])
return netG, netD, optimG, optimD, epoch
save와 load 설정하기
###
# GAN 모델이 Gernerator와 Discriminator 2개의 네트워크를 사용하므로 save, load 도 각각 설정
#train.py
# TRAIN MODE
if mode == 'train':
if train_continue == "on":
netG, netD, optimG, optimD, st_epoch = load(ckpt_dir=ckpt_dir,
netG=netG, netD=netD,
optimG=optimG, optimD=optimD)
train loop 수정
###
# GAN 모델이 Gernerator와 Discriminator 2개의 네트워크를 사용하므로 save, load 도 각각 설정
#train.py
for epoch in range(st_epoch + 1, num_epoch + 1):
netG.train()
netD.train()
loss_G_l1_train = [] # L1 loss 추가
loss_G_gan_train = [] # gan loss 추가
loss_D_real_train = [] # original image의 loss
loss_D_fake_train = [] # Generatior가 생성한 Fake image의 loss
for batch, data in enumerate(loader_train, 1):
# forward pass
label = data['label'].to(device)
# input = torch.randn(label.shape[0], 100, 1, 1,).to(device) #(B, C, H, W) // x= 1, y = 1, ch =100 를 가진 noise 생성
input = data['input'].to(device) # DC GAN과 다르게 Input 데이터가 이미지이기 떄문에 input으로 수정
output = netG(input)
# Discriminator update
real = torch.cat([input, label], dim=1) # 채널방향으로 concat 되어있는 데이터를 Input이미지로 넣어줘야함
fake = torch.cat([input, output], dim=1) # 채널방향으로 concat 되어있는 데이터를 Input이미지로 넣어줘야함
pred_real = netD(real) # label -> real
pred_fake = netD(fake.detach()) # output -> fake
loss_D_real = fn_gan(pred_real, torch.ones_like(pred_real))
loss_D_fake = fn_gan(pred_fake, torch.zeros_like(pred_fake))
loss_D = 0.5 * (loss_D_real + loss_D_fake)
# Generator update
fake = torch.cat([input, output], dim=1)
pred_fake = netD(fake)
loss_G_gan = fn_gan(pred_fake, torch.ones_like(pred_fake))
loss_G_l1 = fn_l1(output, label) # L1 loss 추가
loss_G = loss_G_gan + wgt * loss_G_l1
역전파 추가
def set_requires_grad(nets, requires_grad=False)
# 네트워크의 para에 대하여 grad를 계산할지 말지 정하는 함수
#util.py
def set_requires_grad(nets, requires_grad=False):
"""Set requies_grad=Fasle for all the networks to avoid unnecessary computations
Parameters:
nets (network list) -- a list of networks
requires_grad (bool) -- whether the networks require gradients or not
"""
if not isinstance(nets, list):
nets = [nets]
for net in nets:
if net is not None:
for param in net.parameters():
param.requires_grad = requires_grad
역전파 추가
-
# Discriminator에 역전파 추가
#train.py
# backward netD
set_requires_grad(netD, True) # require가 True 이기 떄문에 Discriminator의 para가 update 수행
optimD.zero_grad()
pred_real = netD(label) # label이라는 original을 넣으면 pred 은 True를 갖기를 원하게 됨
pred_fake = netD(output.detach()) # generator의 output을 넣으면 pred 은 False를 갖기를 원하게 됨
# .detach()로 Discriminator의 backward routine이 Generator로 넘어가지 않도록 연결을 끊어줌
loss_D_real = fn_loss(pred_real, torch.ones_like(pred_real)) # ones_like = True
loss_D_fake = fn_loss(pred_fake, torch.zeros_like(pred_fake)) # zeros_like = False
loss_D = 0.5 * (loss_D_real + loss_D_fake)
loss_D.backward()
optimD.step()
# backward netG
set_requires_grad(netD, False)
optimG.zero_grad()
pred_fake = netD(output) # original value 그대로 사용
loss_G = fn_loss(pred_fake, torch.ones_like(pred_fake)) # 가짜를 진짜처럼 인식하도록 하기위해 ones_line(fake)를 사용
loss_G.backward()
optimG.step()
손실함수 추가
-
# Generator의 손실함수, Discriminator의 real의 손실함수, Discriminator의 fake의 손실함수
#train.py
# 손실함수 계산
loss_G_l1_train += [loss_G_l1.item()] # L1 추가 되어있으므로 추가
loss_G_gan_train += [loss_G_gan.item()]
loss_D_real_train += [loss_D_real.item()]
loss_D_fake_train += [loss_D_fake.item()]
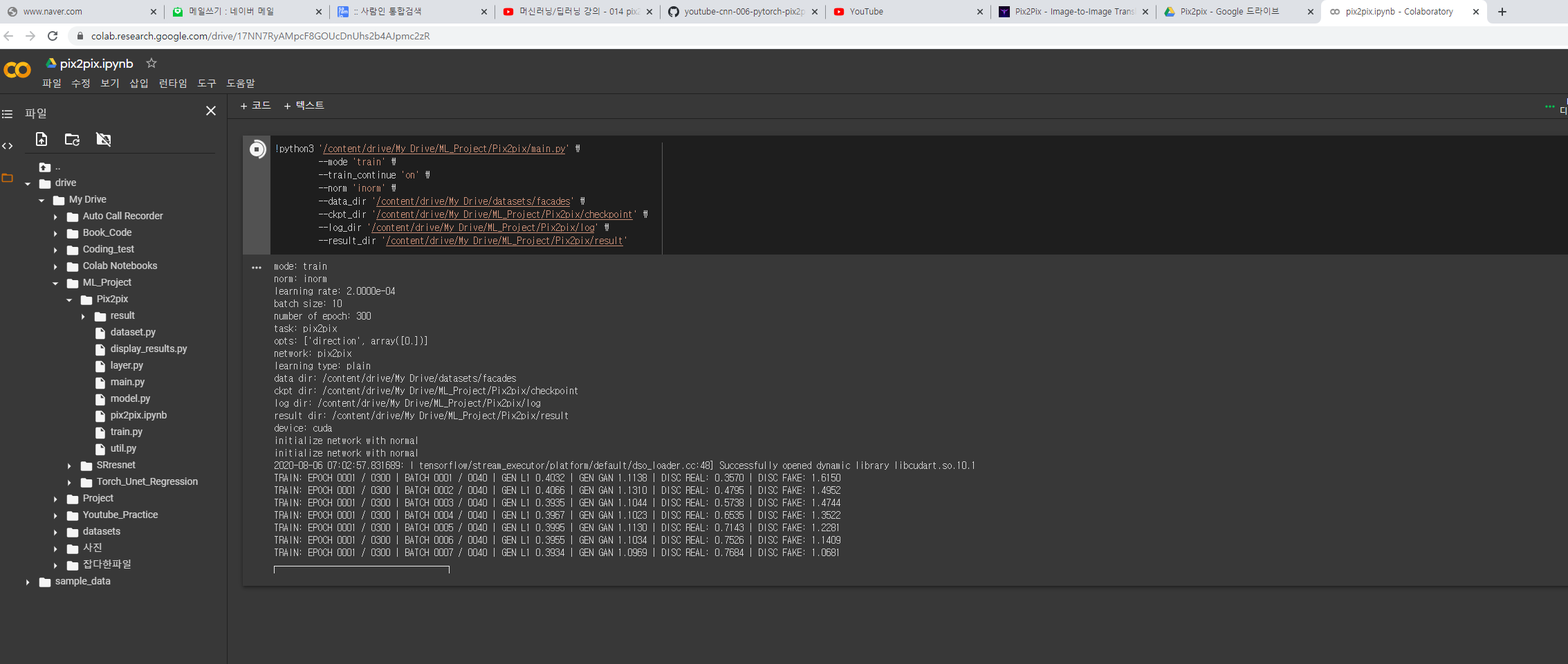
print("TRAIN: EPOCH %04d / %04d | BATCH %04d / %04d | "
"GEN L1 %.4f | GEN GAN %.4f | "
"DISC REAL: %.4f | DISC FAKE: %.4f" %
(epoch, num_epoch, batch, num_batch_train,
np.mean(loss_G_l1_train), np.mean(loss_G_gan_train),
np.mean(loss_D_real_train), np.mean(loss_D_fake_train)))
학습시키기
-
#
#train.py
if batch % 10 == 0:
# Tensorboard 저장하기
# 모두 이미지의 형태로 저장하기때문에 input과 label 추가
input = fn_tonumpy(fn_denorm(input, mean=0.5, std=0.5)).squeeze()
label = fn_tonumpy(fn_denorm(label, mean=0.5, std=0.5)).squeeze()
output = fn_tonumpy(fn_denorm(output, mean=0.5, std=0.5)).squeeze()
input = np.clip(input, a_min=0, a_max=1)
label = np.clip(label, a_min=0, a_max=1)
output = np.clip(output, a_min=0, a_max=1)
id = num_batch_train * (epoch - 1) + batch
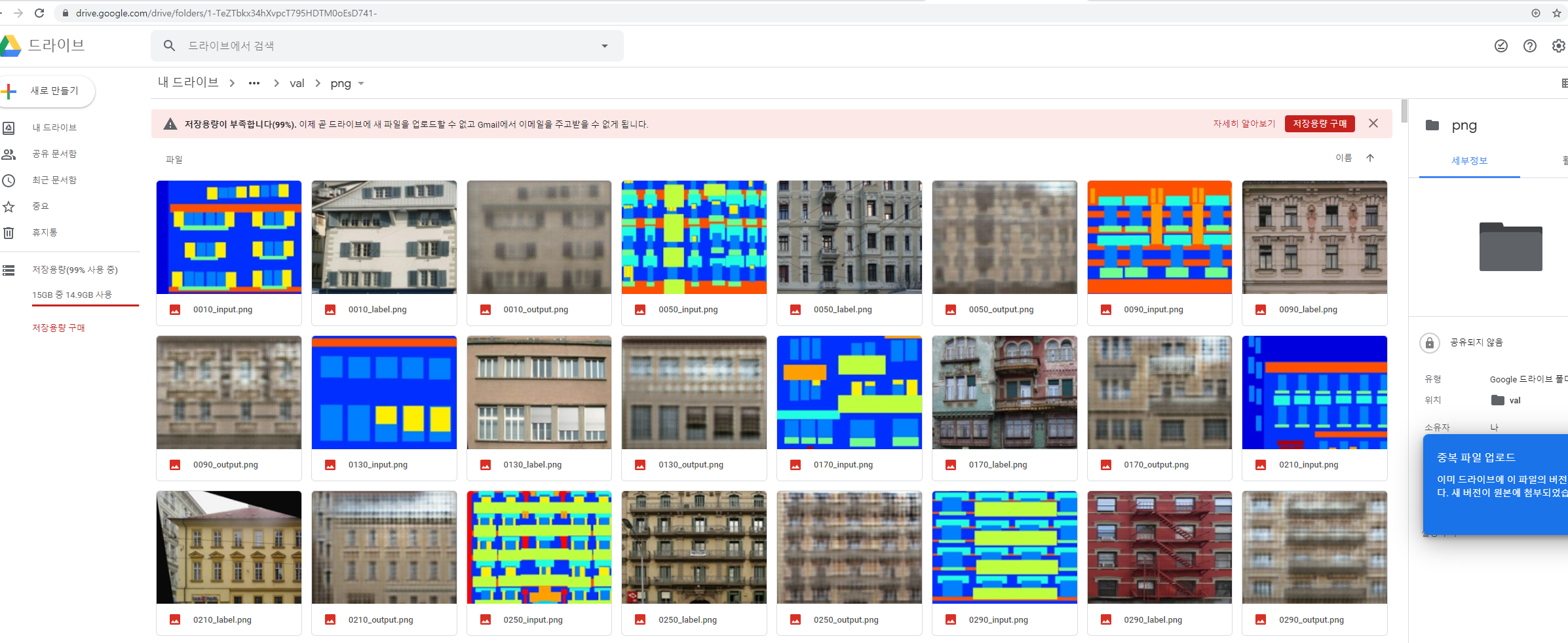
plt.imsave(os.path.join(result_dir_val, 'png', '%04d_input.png' % id), input[0], cmap=cmap)
plt.imsave(os.path.join(result_dir_val, 'png', '%04d_label.png' % id), label[0], cmap=cmap)
plt.imsave(os.path.join(result_dir_val, 'png', '%04d_output.png' % id), output[0], cmap=cmap)
writer_val.add_image('input', input, id, dataformats='NHWC')
writer_val.add_image('label', label, id, dataformats='NHWC')
writer_val.add_image('output', output, id, dataformats='NHWC')
writer_val.add_scalar('loss_G_l1', np.mean(loss_G_l1_val), epoch)
writer_val.add_scalar('loss_G_gan', np.mean(loss_G_gan_val), epoch)
writer_val.add_scalar('loss_D_real', np.mean(loss_D_real_val), epoch)
writer_val.add_scalar('loss_D_fake', np.mean(loss_D_fake_val), epoch)
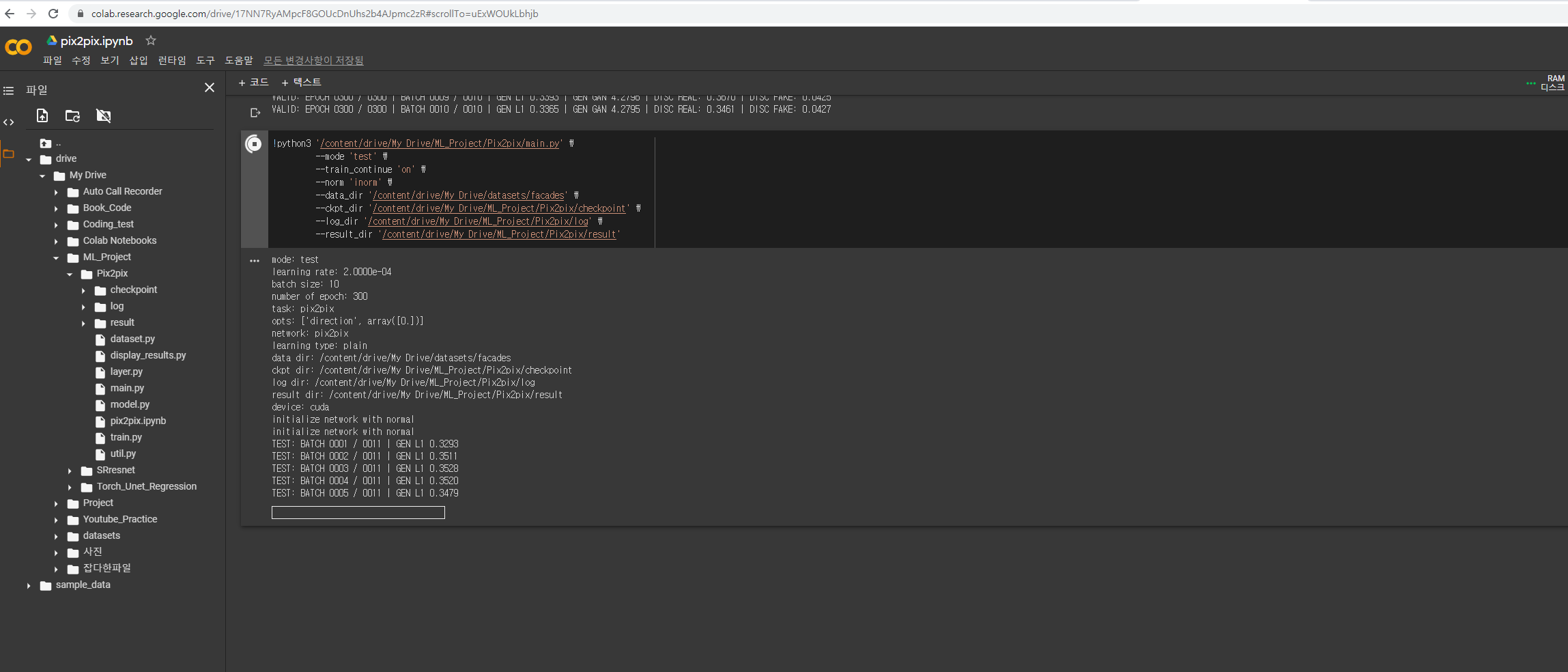
test 하기
-
#
#train.py
wgt = args.wgt # weight arg pasring
dataset_test = Dataset(data_dir=os.path.join(data_dir, 'test'), transform=transform_test, task=task, opts=opts)
## 네트워크 생성하기
elif network == "pix2pix":
netG = Pix2Pix(in_channels=nch, out_channels=nch, nker=nker, norm=norm).to(device)
netD = Discriminator(in_channels=2 * nch, out_channels=1, nker=nker, norm=norm).to(device)
init_weights(netG, init_type='normal', init_gain=0.02)
init_weights(netD, init_type='normal', init_gain=0.02)
## 손실함수 정의하기
fn_l1 = nn.L1Loss().to(device)
fn_gan = nn.BCELoss().to(device)