Model Framework 구축
Sampling 추가하기
def add_sampling(img, type=”random”, opts=None)
#Utils.py
# opts를 통해서 option argument를 전달받아서 사용
ds_y = opts[0].astype(np.int) # int 형으로 convert 될수 있도록 astype으로 설정
# 가우시안 샘플링에서 채널방향으로 샘플링이 될수 있는도록 하는 코드
gaus = a * np.exp(-((x - x0)**2/(2*sgmx**2) + (y - y0)**2/(2*sgmy**2)))
gaus = np.tile(gaus[:, :, np.newaxis], (1, 1, sz[2]))
rnd = np.random.rand(sz[0], sz[1], sz[2])
msk = (rnd < gaus).astype(np.float)
Noise 추가하기
def add_noise(img, type=”random”, opts=None)
#Utils.py
# opts를 통해서 option argument를 전달받아서 사용
sgm = opts[0] # sigma parameter
# 포와송 패키지 추가
from scipy.stats import poisson
elif type == "poisson":
dst = poisson.rvs(255.0 * img) / 255.0
noise = dst - img
Blurring 추가하기
def add_blur(img, type=”bilinear”, opts=None)
#Utils.py
# opts를 통해서 option argument를 전달받아서 사용
ds = opts[0] # resolution scale downsampling
keepdim = opts[1] # down Sampling을 수행한 Demansion을 원래 Input영상으로
# 되돌릴지 유지할지 결정할 flag
# rescale을 하는 TYPE은 IF 문으로 빼서 tpye별로 사용
nearest, bilinear, biquadratic, ....
# rescale 함수 추가
from skimage.transform import rescale, resize
# rescale 함수는 downsampling의 ratio를 이용해서 size를 조절
dst = rescale(img, scale=(dw, dw, 1), order=order)
# resize 함수는 output_shape를 고정해서 해당 shape에 맞게끔 조절
dst = resize(img, output_shape=(sz[0] // opts[0], sz[1] // opts[0], sz[2]), order=order)
parser 생성하기
-
#train.py
parser = argparse.ArgumentParser(description="Regression Tasks such as inpainting, denoising, and super_resolution",
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument("--mode", default="train", choices=["train", "test"], type=str, dest="mode")
parser.add_argument("--train_continue", default="off", choices=["on", "off"], type=str, dest="train_continue")
parser.add_argument("--lr", default=1e-3, type=float, dest="lr")
parser.add_argument("--batch_size", default=4, type=int, dest="batch_size")
parser.add_argument("--num_epoch", default=100, type=int, dest="num_epoch")
parser.add_argument("--data_dir", default="./datasets/BSR/BSDS500/data/images", type=str, dest="data_dir")
parser.add_argument("--ckpt_dir", default="./checkpoint/inpainting/plain", type=str, dest="ckpt_dir")
parser.add_argument("--log_dir", default="./log/inpainting/plain", type=str, dest="log_dir")
parser.add_argument("--result_dir", default="./result/inpainting/plain", type=str, dest="result_dir")
# cohices를 사용하면 list의 것만 추가됨
parser.add_argument("--task", default="super_resolution", choices=["inpainting", "denoising", "super_resolution"],
type=str, dest="task")
# nargs='+' 여러개의 arg를 하나의 variable로 받을 수 있음
parser.add_argument('--opts', nargs='+', default=['bilinear', 4], dest='opts')
# img 관련 arg 추가
parser.add_argument("--ny", default=320, type=int, dest="ny")
parser.add_argument("--nx", default=480, type=int, dest="nx")
parser.add_argument("--nch", default=3, type=int, dest="nch")
parser.add_argument("--nker", default=64, type=int, dest="nker")
# network를 선택할 수 있는 arg 추가
parser.add_argument("--network", default="unet", choices=["unet", "hourglass"], type=str, dest="network")
parser.add_argument("--learning_type", default="plain", choices=["plain", "residual"], type=str, dest="learning_type")
args = parser.parse_args()order=order)
트레이닝 파라미터 추가하기
-
#train.py
# opts를 통해서 option argument를 전달받아서 사용
opts = [args.opts[0], np.asarray(args.opts[1:]).astype(np.float)]
# 첫번째는 tpye을 설정하는 값, 나머지값은 숫자로 받기때문에 array로 받음
ny = args.ny
nx = args.nx
nch = args.nch
nker = args.nker
network = args.network
learning_type = args.learning_type
result dir 추가하기
-
#train.py
result_dir_train = os.path.join(result_dir, 'train')
result_dir_val = os.path.join(result_dir, 'val')
result_dir_test = os.path.join(result_dir, 'test')
# train 에서는 png만 test에서는 png, numpy값까지 받을수 있게끔 설정
if not os.path.exists(result_dir):
os.makedirs(os.path.join(result_dir_train, 'png'))
# os.makedirs(os.path.join(result_dir_train, 'numpy'))
os.makedirs(os.path.join(result_dir_val, 'png'))
# os.makedirs(os.path.join(result_dir_val, 'numpy'))
os.makedirs(os.path.join(result_dir_test, 'png'))
os.makedirs(os.path.join(result_dir_test, 'numpy'))
crop 생성(crop =컴퓨터 그래픽(스)에서 필요 없는 부분을 잘라 내는 작업.)
class RandomCrop(object)
#datasets.py
def __init__(self, shape):
self.shape = shape
def __call__(self, data):
# input, label = data['input'], data['label']
# h, w = input.shape[:2]
h, w = data['label'].shape[:2]
new_h, new_w = self.shape
# 0에서 original과 새로운 crop될 size의 차 사이에서 도출
top = np.random.randint(0, h - new_h)
left = np.random.randint(0, w - new_w)
id_y = np.arange(top, top + new_h, 1)[:, np.newaxis]
id_x = np.arange(left, left + new_w, 1)
# input = input[id_y, id_x]
# label = label[id_y, id_x]
# data = {'label': label, 'input': input}
# Updated at Apr 5 2020
for key, value in data.items():
data[key] = value[id_y, id_x]
return data
Normalization
class Normalization(object)
#datasets.py
def __init__(self, mean=0.5, std=0.5):
self.mean = mean
self.std = std
def __call__(self, data):
# label, input = data['label'], data['input']
#
# input = (input - self.mean) / self.std
# label = (label - self.mean) / self.std
#
# data = {'label': label, 'input': input}
# Updated at Apr 5 2020
for key, value in data.items():
data[key] = (value - self.mean) / self.std
return data
네트워크 학습하기
-
#train.py
if mode == 'train':
# crop 적용
transform_train = transforms.Compose([RandomCrop(shape=(ny, nx)), Normalization(mean=0.5, std=0.5), RandomFlip()])
transform_val = transforms.Compose([RandomCrop(shape=(ny, nx)), Normalization(mean=0.5, std=0.5)])
else:
# crop 적용
transform_test = transforms.Compose([RandomCrop(shape=(ny, nx)), Normalization(mean=0.5, std=0.5)])
데이터 로더 구현하기
class Dataset(torch.utils.data.Dataset)
#datasets.py
lst_data = os.listdir(self.data_dir)
# 확장자가 등록된 것만 list에 담음
lst_data = [f for f in lst_data if f.endswith('jpg') | f.endswith('jpeg') | f.endswith('png')]
lst_data.sort()
# dataset이 png 파일이므로 matplotlib를 이용해서 data load
import matplotlib.pyplot as plt
img = plt.imread(os.path.join(self.data_dir, self.lst_data[index]))
# 정규화 하기
sz = img.shape # 뒤족박죽으로 data 저장됨
if sz[0] > sz[1]:
img = img.transpose((1, 0, 2)) # 항상 가로로 길게끔 transpose
if img.ndim == 2:
img = img[:, :, np.newaxis] # 이미지가 x,y만 있을때 채널방향으로 사이즈 변경
if img.dtype == np.uint8:
img = img / 255.0 # image normalization
# task에 맞게끔 arg 추가하기
from Torch_Unet_regression.util import *
def __init__(self, data_dir, transform=None, task=None, opts=None)
self.task = task
self.opts = opts
def __getitem__(self, index)
if self.task == "inpainting":
data['input'] = add_sampling(data['label'], type=self.opts[0], opts=self.opts[1])
elif self.task == "denoising":
data['input'] = add_noise(data['label'], type=self.opts[0], opts=self.opts[1])
if self.transform:
data = self.transform(data)
if self.task == "super_resolution":
data['input'] = add_blur(data['label'], type=self.opts[0], opts=self.opts[1])
data = self.to_tensor(data)
return data
네트워크 학습하기
-
#train.py
if mode == 'train':
# task와 opt para를 넘길 수 있도록 설정
dataset_train = Dataset(data_dir=os.path.join(data_dir, 'train'), transform=transform_train, task=task, opts=opts)
loader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True, num_workers=0)
else:
# task와 opt para를 넘길 수 있도록 설정
dataset_test = Dataset(data_dir=os.path.join(data_dir, 'test'), transform=transform_test, task=task, opts=opts)
loader_test = DataLoader(dataset_test, batch_size=batch_size, shuffle=False, num_workers=0)
네트워크 추가하기
-
#train.py
# parser로 network를 type별로 선택할 수 있도록 추가
parser.add_argument("--network", default="unet", choices=["unet", "hourglass"], type=str, dest="network")
if network == "unet":
net = UNet(nch=nch, nker=nker, learning_type=learning_type).to(device)
elif network == "hourglass":
net = Hourglass(nch=nch, nker=nker, learning_type=learning_type).to(device)
layer 추가하기
class CBR2d(nn.Module)
#layer.py
# 추가할 모듈을 import를 받을 수 있게끔 새로운 파일로 저장
class CBR2d(nn.Module): # CBR 모듈도 nn 모듈을 상속을 받을 수 있게끔 class로 작성
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=True, norm="bnorm", relu=0.0):
super().__init__()
layers = []
layers += [nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding,
bias=bias)]
if not norm is None:
if norm == "bnorm":
layers += [nn.BatchNorm2d(num_features=out_channels)]
elif norm == "inorm":
layers += [nn.InstanceNorm2d(num_features=out_channels)]
if not relu is None and relu >= 0.0:
layers += [nn.ReLU() if relu == 0 else nn.LeakyReLU(relu)]
self.cbr = nn.Sequential(*layers)
def forward(self, x):
return self.cbr(x)
손실함수 수정하기
-
#train.py
# BinaryCorossEntrophy -> segmentation을 수행하기 위한 loss function
# Regression or restoration -> L1 or L2 loss function 필요
# fn_loss = nn.BCEWithLogitsLoss().to(device)
fn_loss = nn.MSELoss().to(device)
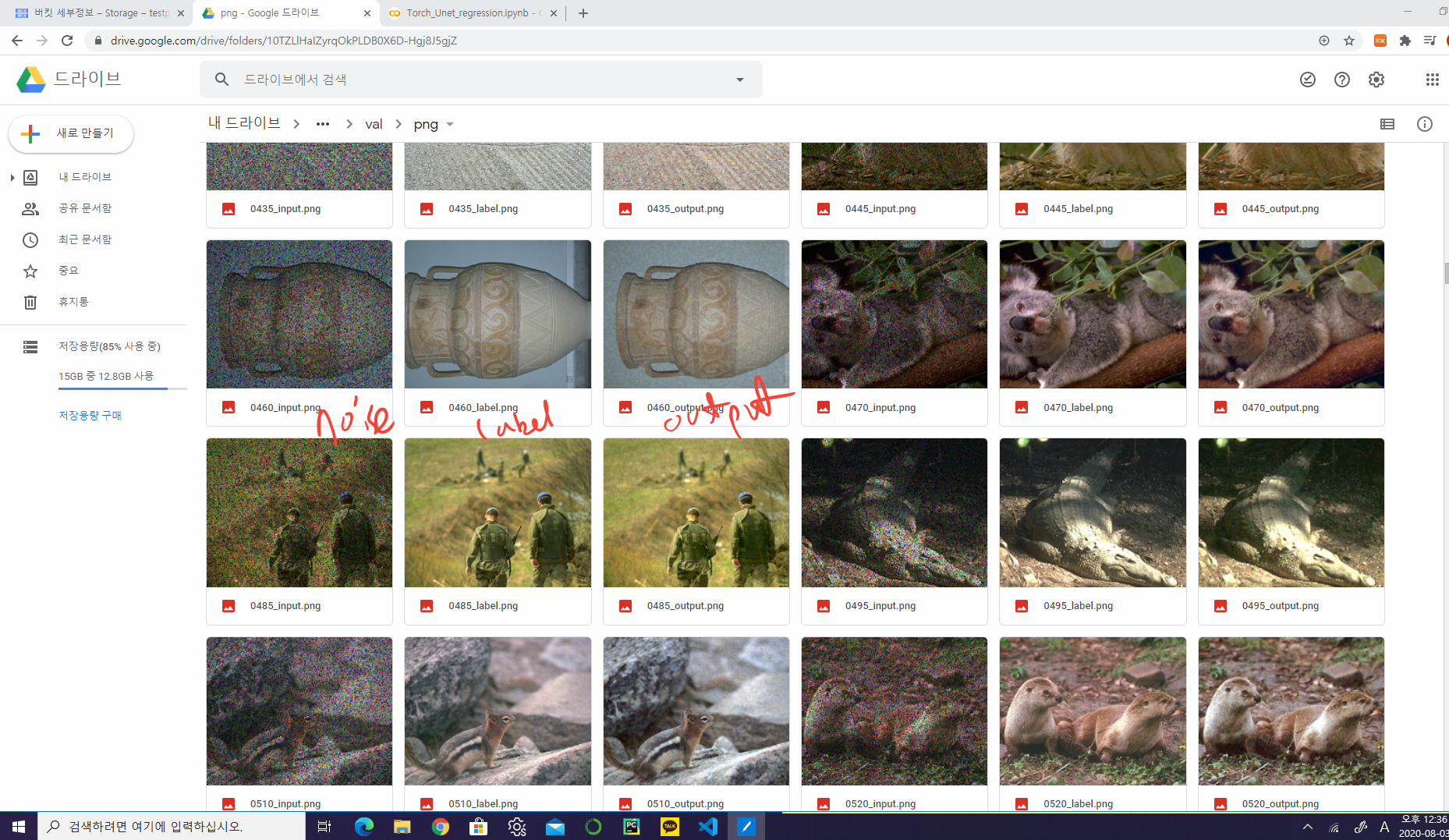
결과 이미지 저장하기
-
#train.py
if mode == 'train':
# maxrix를 0~1로 cliping을 해줌
# cliping = 허용하는 한계 입력 또는 한계 출력을 넘어설 때 문제 발생을 방지
input = np.clip(input, a_min=0, a_max=1)
output = np.clip(output, a_min=0, a_max=1)
id = num_batch_train * (epoch - 1) + batch
# batch중 첫번째 배치의 이미지만 저장
plt.imsave(os.path.join(result_dir_train, 'png', '%04d_label.png' % id), label[0].squeeze(), cmap=cmap)
plt.imsave(os.path.join(result_dir_train, 'png', '%04d_input.png' % id), input[0].squeeze(), cmap=cmap)
plt.imsave(os.path.join(result_dir_train, 'png', '%04d_output.png' % id), output[0].squeeze(),cmap=cmap)
else:
# maxrix를 0~1로 cliping을 해줌
# cliping = 허용하는 한계 입력 또는 한계 출력을 넘어설 때 문제 발생을 방지
label_ = np.clip(label_, a_min=0, a_max=1)
input_ = np.clip(input_, a_min=0, a_max=1)
output_ = np.clip(output_, a_min=0, a_max=1)
# batch중 첫번째 배치의 이미지만 저장
plt.imsave(os.path.join(result_dir_test, 'png', '%04d_label.png' % id), label_, cmap=cmap)
plt.imsave(os.path.join(result_dir_test, 'png', '%04d_input.png' % id), input_, cmap=cmap)
plt.imsave(os.path.join(result_dir_test, 'png', '%04d_output.png' % id), output_, cmap=cmap)
Residual Learning
network의 학습을 부분적으로 함으로써 효율화
-
# model의 arg -> learming_type 추가
#train.py
parser.add_argument("--learning_type", default="plain", choices=["plain", "residual"], type=str, dest="learning_type")
learning_type = args.learning_type
if network == "unet":
net = UNet(nch=nch, nker=nker, learning_type=learning_type).to(device)