SPARK
SPARK Tutorial
- 빅데이터, 하둡 및 스파크 소개
- 스파크 배포
- 스파크 클러스터 아키텍처의 이해
- 스파크 프로그래밍 기초 학습
- 스파크 코어 API를 사용한 고급 프로그래밍
- 스파크로 SQL 및 NoSQL 프로그래밍하기
- 스파크를 사용한 스트림 처리 및 메시징
- 스파크를 사용한 데이터 과학 및 머신러닝 소개
![]()
이탤릭 볼드 이탤릭볼드
Overview
- HADOOP, SPARK
- HDFS YARN
- 맵리듀스 vs 분산 데이터 집합
- 스파크 사용
- 스파크 응용 프로그램의 입력/출력 유형
- 스파크의 리소스 스케줄러로서의 YARN
Hadoop, Spark
빅데이터 처리 위해 태어난 분산시스템
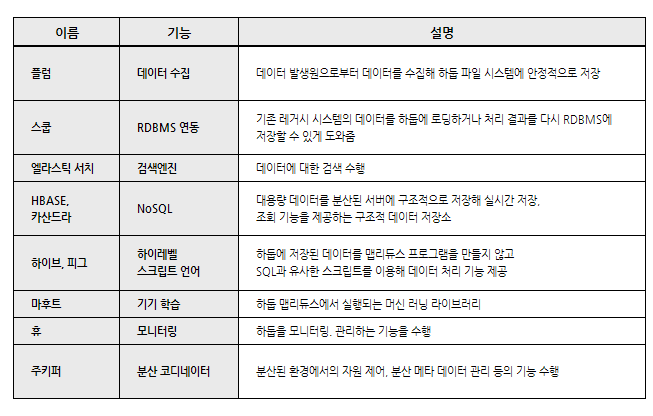
HDFS
- 대용량 데이터을 분산시키고 저장하고 관리하는 하둡 분산 파일 시스템(HDFS)
- 다수의 리눅스 서버에 설치되어 운영
- 저장하고자 하는 파일을 블록 단위로 나누어 분산된 서버에 저장
- 네임노드(NameNode), 다수의 데이터노드(DataNode)로 구성
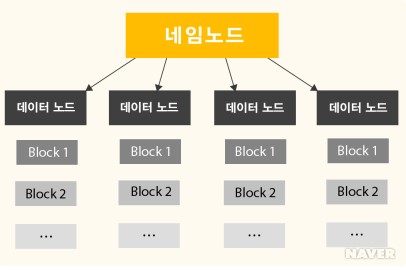
YARN
프로세싱 또는 리소스 스케줄링 서브시스템
- 하둡의 데이터 처리를 제어하고 조율
- 클라이언트가 리소스 매니저에게 응용프로그램 제출
- 리소스 매니저는 충분한 용량을 가진 노드 매니저에 애플리케이션 마스터 프로세스 할당
- 애플리케이션 마스터는 노드 매니저에서 실행할 리소스 매니저와 작업 컨테이너를 협상, 응용 프로그램의 작업 컨테이너를 호스팅하는 노드 매니저로 프로세스 전달
- 노드 매니저는 작업 시도 상태와 진행상황을 애플리케이션 마스터에 보고
- 애플리케이션 마스터는 진행률과 응용 프로그램의 상태를 리소스 매니저에 보고
- 리소스 메니저는 응용프로그램 진행률, 상태 및 결과를 클라이언트에 보고
HADOOP Tutorial
https://kontext.tech/column/hadoop/377/latest-hadoop-321-installation-on-windows-10-step-by-step-guide#comment314
- 하둡 다운로드
다운받은 파일 압축풀기. 알집으로 풀면 Name 떄문에 뻑나니까 shell로 풀기
!tar -xvzf hadoop-3.2.1.tar.gz
- 윈도우에서 쓸 수 있도록 Utils 가져오기
https://github.com/cdarlint/winutils/tree/master/hadoop-3.2.1/bin
버전에 맞게끔 가져오기 . 본인은 3.2.1 사용
가져온 파일 하둡 폴더 bin에 복사 붙여넣기
-
주변 유틸도 필요함 JAVA JDK , MAVEN 등등 설치
-
환경변수 설정 JAVA와 HADOOP 및 기타 프로그램들 환경변수 설정 HADOOP의 경우 JAVA의 path가 programfile에 있으면 안됨. 다른 폴더 C:\나 D:\에 새로 설치 (로컬에서 사용하려면 D:\ 추천)
-
HADOOP Config 수정
CONFIG 정보를 수정해줘야함.
HADOOP 의 etc 폴더안에 config xml 있는데 복붙해줌
core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://0.0.0.0:19000</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///D:/Hadoop/data/dfs/namespace_logs</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///D:/Hadoop/data/dfs/data</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>%HADOOP_HOME%/share/hadoop/mapreduce/*,%HADOOP_HOME%/share/hadoop/mapreduce/lib/*,%HADOOP_HOME%/share/hadoop/common/*,%HADOOP_HOME%/share/hadoop/common/lib/*,%HADOOP_HOME%/share/hadoop/yarn/*,%HADOOP_HOME%/share/hadoop/yarn/lib/*,%HADOOP_HOME%/share/hadoop/hdfs/*,%HADOOP_HOME%/share/hadoop/hdfs/lib/*</value>
</property>
</configuration>
- HDFS, YARN 데몬 돌리기
prompt 에서 돌리기
!%HADOOP_HOME%\sbin\start-dfs.cmd # 하둡 설치한 폴더가서 실행
!%HADOOP_HOME%\sbin\start-yarn.cmd # 하둡 설치한 폴더가서 실행
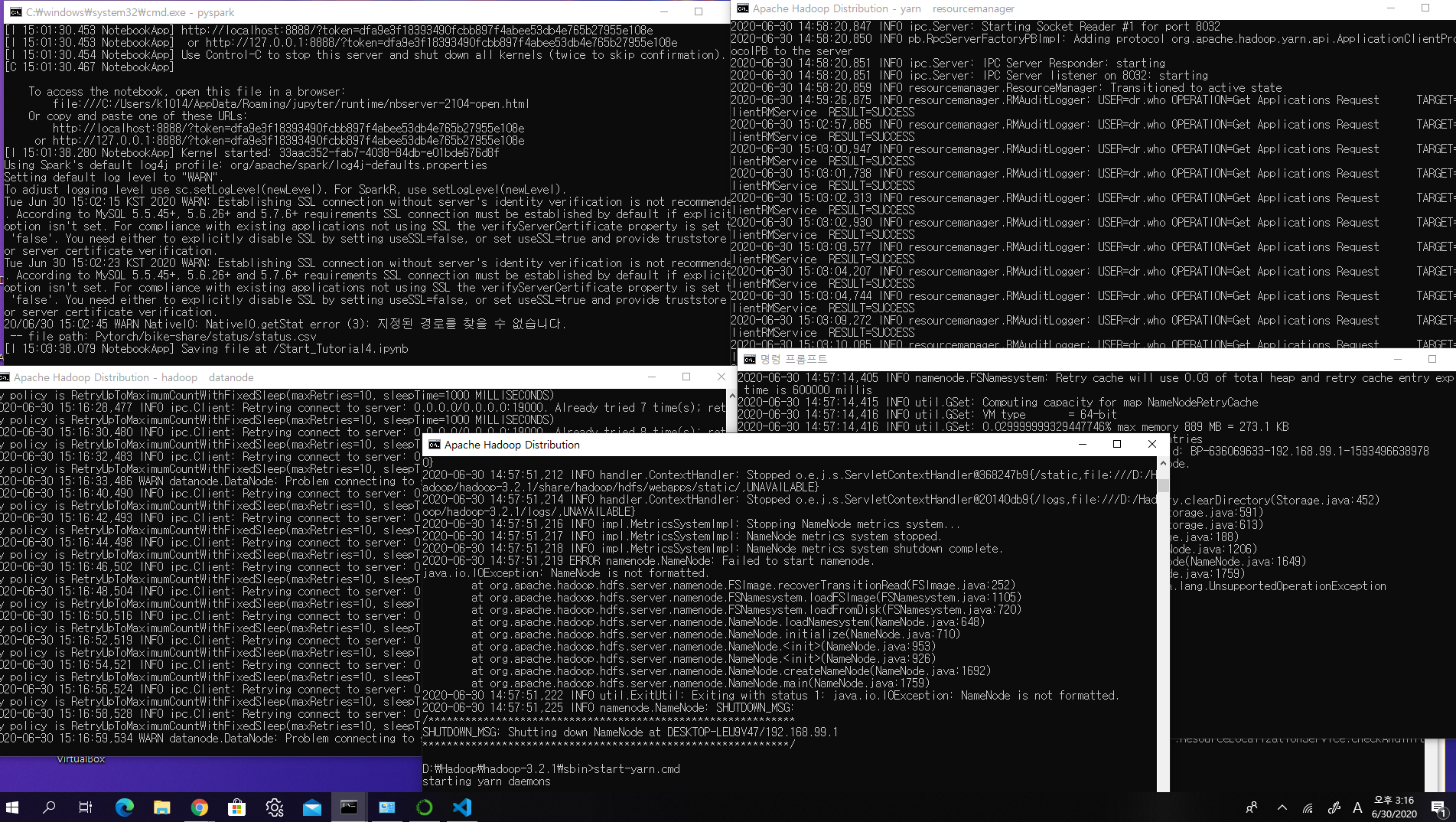
이후 pyspark 를 jupyter 노트북에 연결해서 잘 쓰면됨~~~~~