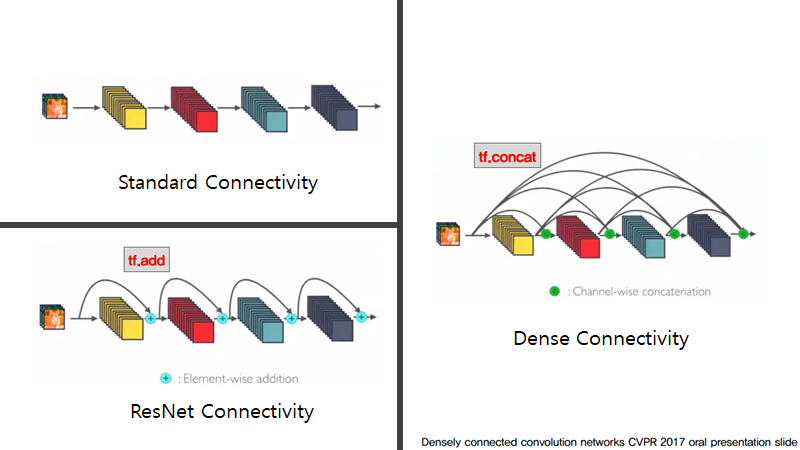
DenseNet
일반적인 네트워크 구조는 위에서 수식으로 간단히 나타냈지만 convolution, activation, pooling의 순차적인 조합입니다. ResNet은 이러한 네트워크에 skip connection을 추가해서 degradation problem을 (논문 저자들의 주장에 따르면)해소했습니다. 이에 더해 DenseNet에서는 Dense connectivity라는 새로운 개념을 추가하게 됩니다.
쉽게 얘기하자면 제가 쓰는 텐서플로우 기준으로 ResNet은 tf.add를 사용하여 직전 부분을 더해주는 것이고 DenseNet은 tf.concat을 써서 거쳐왔던 부분들을 전부 쌓는다고 보시면 됩니다.
즉, 네트워크가 깊어질수록 처음에 가지고 있던 정보가 사라지거나 “wash out”되어버릴 수 있다는 것입니다.
DenseNet에서는 이 문제를 처음 쌓은 층을 네트워크가 깊어져도 계속 차곡차곡 쌓아가는 것으로 해결할 수 있다고 얘기합니다. 이렇게 차곡차곡쌓은 모습이 밀도가 굉장히 높은 모습을 보여주어 Dense Convolutional Network라고 이름을 붙였다고 합니다.
Dense connectivity advantages
- They alleviate the vanishing-gradient problem
- Strengthen feature propagation
- Encourage feature reuse
- Substantially reduce the number of parameters(less complexity)
- Reduce overfitting on tasks with smaller training set sizes.

이탤릭 볼드 이탤릭볼드
Workflow stages
- Question or problem definition.
- Acquire training and testing data.
- Wrangle, prepare, cleanse the data.
- Analyze, identify patterns, and explore the data.
- Model, predict and solve the problem.
- Visualize, report, and present the problem solving steps and final solution.
- Supply or submit the results.
기본적으로 설치되어 있어야하는 패키지는 아래 코드 를 사용한다.
import math, re, os
import tensorflow as tf, tensorflow.keras.backend as K
import numpy as np
from matplotlib import pyplot as plt
from kaggle_datasets import KaggleDatasets
import efficientnet.tfkeras as efn
from sklearn.metrics import f1_score, precision_score, recall_score, confusion_matrix
from tensorflow.keras.applications import DenseNet201
print("Tensorflow version " + tf.__version__)
AUTO = tf.data.experimental.AUTOTUNE
TPU or GPU detection
# Detect hardware, return appropriate distribution strategy
try:
tpu = tf.distribute.cluster_resolver.TPUClusterResolver() # TPU detection. No parameters necessary if TPU_NAME environment variable is set. On Kaggle this is always the case.
print('Running on TPU ', tpu.master())
except ValueError:
tpu = None
if tpu:
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
strategy = tf.distribute.experimental.TPUStrategy(tpu)
else:
strategy = tf.distribute.get_strategy() # default distribution strategy in Tensorflow. Works on CPU and single GPU.
print("REPLICAS: ", strategy.num_replicas_in_sync)
Competition data access
TPUs read data directly from Google Cloud Storage (GCS). This Kaggle utility will copy the dataset to a GCS bucket co-located with the TPU. If you have multiple datasets attached to the notebook, you can pass the name of a specific dataset to the get_gcs_path function. The name of the dataset is the name of the directory it is mounted in. Use !ls /kaggle/input/ to list attached datasets.
GCP 버킷 접근
!git clone https://github.com/GoogleCloudPlatform/gcsfuse.git
!echo "deb http://packages.cloud.google.com/apt gcsfuse-bionic main" > /etc/apt/sources.list.d/gcsfuse.list
!curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
!apt -qq update
!apt -qq install gcsfuse
GCP Bucket 연동
GCS_DS_PATH = KaggleDatasets().get_gcs_path() # you can list the bucket with "!gsutil ls $GCS_DS_PATH"
Configuration
# Data access
GCS_DS_PATH = KaggleDatasets().get_gcs_path()
# Configuration
IMAGE_SIZE = [512, 512]
EPOCHS = 20
BATCH_SIZE = 16 * strategy.num_replicas_in_sync
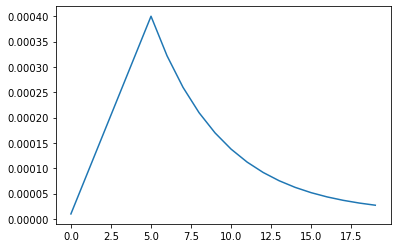
Custom LR schedule
LR_START = 0.00001
LR_MAX = 0.00005 * strategy.num_replicas_in_sync
LR_MIN = 0.00001
LR_RAMPUP_EPOCHS = 5
LR_SUSTAIN_EPOCHS = 0
LR_EXP_DECAY = .8
def lrfn(epoch):
if epoch < LR_RAMPUP_EPOCHS:
lr = (LR_MAX - LR_START) / LR_RAMPUP_EPOCHS * epoch + LR_START
elif epoch < LR_RAMPUP_EPOCHS + LR_SUSTAIN_EPOCHS:
lr = LR_MAX
else:
lr = (LR_MAX - LR_MIN) * LR_EXP_DECAY**(epoch - LR_RAMPUP_EPOCHS - LR_SUSTAIN_EPOCHS) + LR_MIN
return lr
lr_callback = tf.keras.callbacks.LearningRateScheduler(lrfn, verbose=True)
rng = [i for i in range(EPOCHS)]
y = [lrfn(x) for x in rng]
plt.plot(rng, y)
print("Learning rate schedule: {:.3g} to {:.3g} to {:.3g}".format(y[0], max(y), y[-1]))
config dataset
GCS_PATH_SELECT = { # available image sizes
192: GCS_DS_PATH + '/tfrecords-jpeg-192x192',
224: GCS_DS_PATH + '/tfrecords-jpeg-224x224',
331: GCS_DS_PATH + '/tfrecords-jpeg-331x331',
512: GCS_DS_PATH + '/tfrecords-jpeg-512x512'
}
GCS_PATH = GCS_PATH_SELECT[IMAGE_SIZE[0]]
TRAINING_FILENAMES = tf.io.gfile.glob(GCS_PATH + '/train/*.tfrec')
VALIDATION_FILENAMES = tf.io.gfile.glob(GCS_PATH + '/val/*.tfrec')
TEST_FILENAMES = tf.io.gfile.glob(GCS_PATH + '/test/*.tfrec') # predictions on this dataset should be submitted for the competition
# watch out for overfitting!
SKIP_VALIDATION = True
if SKIP_VALIDATION:
TRAINING_FILENAMES = TRAINING_FILENAMES + VALIDATION_FILENAMES
## V20
# VALIDATION_MISMATCHES_IDS = ['861282b96','df1fd14b4','b402b6acd','741999f79','4dab7fa08','6423cd23e','617a30d60','87d91aefb','2023d3cac','5f56bcb7f','4571b9509','f4ec48685','f9c50db87','96379ff01','28594d9ce','6a3a28a06','fbd61ef17','55a883e16','83a80db99','9ee42218f','b5fb20185','868bf8b0c','d0caf04b9','ef945a176','9b8f2f5bd','f8da3867d','0bf0b39b3','bab3ef1f5','293c37e25','f739f3e83','5253af526','f27f9a100','077803f97','b4becad84']
## V22
# VALIDATION_MISMATCHES_IDS = ['861282b96','617a30d60','4571b9509','f4ec48685','28594d9ce','6a3a28a06','55a883e16','9b8f2f5bd','293c37e25']
## V23
VALIDATION_MISMATCHES_IDS = []
CLASSES = ['pink primrose', 'hard-leaved pocket orchid', 'canterbury bells', 'sweet pea', 'wild geranium', 'tiger lily', 'moon orchid', 'bird of paradise', 'monkshood', 'globe thistle', # 00 - 09
'snapdragon', "colt's foot", 'king protea', 'spear thistle', 'yellow iris', 'globe-flower', 'purple coneflower', 'peruvian lily', 'balloon flower', 'giant white arum lily', # 10 - 19
'fire lily', 'pincushion flower', 'fritillary', 'red ginger', 'grape hyacinth', 'corn poppy', 'prince of wales feathers', 'stemless gentian', 'artichoke', 'sweet william', # 20 - 29
'carnation', 'garden phlox', 'love in the mist', 'cosmos', 'alpine sea holly', 'ruby-lipped cattleya', 'cape flower', 'great masterwort', 'siam tulip', 'lenten rose', # 30 - 39
'barberton daisy', 'daffodil', 'sword lily', 'poinsettia', 'bolero deep blue', 'wallflower', 'marigold', 'buttercup', 'daisy', 'common dandelion', # 40 - 49
'petunia', 'wild pansy', 'primula', 'sunflower', 'lilac hibiscus', 'bishop of llandaff', 'gaura', 'geranium', 'orange dahlia', 'pink-yellow dahlia', # 50 - 59
'cautleya spicata', 'japanese anemone', 'black-eyed susan', 'silverbush', 'californian poppy', 'osteospermum', 'spring crocus', 'iris', 'windflower', 'tree poppy', # 60 - 69
'gazania', 'azalea', 'water lily', 'rose', 'thorn apple', 'morning glory', 'passion flower', 'lotus', 'toad lily', 'anthurium', # 70 - 79
'frangipani', 'clematis', 'hibiscus', 'columbine', 'desert-rose', 'tree mallow', 'magnolia', 'cyclamen ', 'watercress', 'canna lily', # 80 - 89
'hippeastrum ', 'bee balm', 'pink quill', 'foxglove', 'bougainvillea', 'camellia', 'mallow', 'mexican petunia', 'bromelia', 'blanket flower', # 90 - 99
'trumpet creeper', 'blackberry lily', 'common tulip', 'wild rose'] # 100 - 102
Helper Functions
vi# Helper Functions
Visualizationsu
# numpy and matplotlib defaults
np.set_printoptions(threshold=15, linewidth=80)
def batch_to_numpy_images_and_labels(data):
images, labels = data
numpy_images = images.numpy()
numpy_labels = labels.numpy()
if numpy_labels.dtype == object: # binary string in this case, these are image ID strings
numpy_labels = [None for _ in enumerate(numpy_images)]
# If no labels, only image IDs, return None for labels (this is the case for test data)
return numpy_images, numpy_labels
def title_from_label_and_target(label, correct_label):
if correct_label is None:
return CLASSES[label], True
correct = (label == correct_label)
return "{} [{}{}{}]".format(CLASSES[label], 'OK' if correct else 'NO', u"\u2192" if not correct else '',
CLASSES[correct_label] if not correct else ''), correct
def display_one_flower(image, title, subplot, red=False, titlesize=16):
plt.subplot(*subplot)
plt.axis('off')
plt.imshow(image)
if len(title) > 0:
plt.title(title, fontsize=int(titlesize) if not red else int(titlesize/1.2), color='red' if red else 'black', fontdict={'verticalalignment':'center'}, pad=int(titlesize/1.5))
return (subplot[0], subplot[1], subplot[2]+1)
def display_batch_of_images(databatch, predictions=None, figsize = 13.0):
"""This will work with:
display_batch_of_images(images)
display_batch_of_images(images, predictions)
display_batch_of_images((images, labels))
display_batch_of_images((images, labels), predictions)
"""
# data
images, labels = batch_to_numpy_images_and_labels(databatch)
if labels is None:
labels = [None for _ in enumerate(images)]
# auto-squaring: this will drop data that does not fit into square or square-ish rectangle
rows = int(math.sqrt(len(images)))
cols = len(images)//rows
# size and spacing
FIGSIZE = figsize
SPACING = 0.1
subplot=(rows,cols,1)
if rows < cols:
plt.figure(figsize=(FIGSIZE,FIGSIZE/cols*rows))
else:
plt.figure(figsize=(FIGSIZE/rows*cols,FIGSIZE))
# display
for i, (image, label) in enumerate(zip(images[:rows*cols], labels[:rows*cols])):
title = '' if label is None else CLASSES[label]
correct = True
if predictions is not None:
title, correct = title_from_label_and_target(predictions[i], label)
dynamic_titlesize = FIGSIZE*SPACING/max(rows,cols)*40+3 # magic formula tested to work from 1x1 to 10x10 images
subplot = display_one_flower(image, title, subplot, not correct, titlesize=dynamic_titlesize)
#layout
plt.tight_layout()
if label is None and predictions is None:
plt.subplots_adjust(wspace=0, hspace=0)
else:
plt.subplots_adjust(wspace=SPACING, hspace=SPACING)
plt.show()
def display_confusion_matrix(cmat, score, precision, recall):
plt.figure(figsize=(15,15))
ax = plt.gca()
ax.matshow(cmat, cmap='Reds')
ax.set_xticks(range(len(CLASSES)))
ax.set_xticklabels(CLASSES, fontdict={'fontsize': 7})
plt.setp(ax.get_xticklabels(), rotation=45, ha="left", rotation_mode="anchor")
ax.set_yticks(range(len(CLASSES)))
ax.set_yticklabels(CLASSES, fontdict={'fontsize': 7})
plt.setp(ax.get_yticklabels(), rotation=45, ha="right", rotation_mode="anchor")
titlestring = ""
if score is not None:
titlestring += 'f1 = {:.3f} '.format(score)
if precision is not None:
titlestring += '\nprecision = {:.3f} '.format(precision)
if recall is not None:
titlestring += '\nrecall = {:.3f} '.format(recall)
if len(titlestring) > 0:
ax.text(101, 1, titlestring, fontdict={'fontsize': 18, 'horizontalalignment':'right', 'verticalalignment':'top', 'color':'#804040'})
plt.show()
def display_training_curves(training, validation, title, subplot):
if subplot%10==1: # set up the subplots on the first call
plt.subplots(figsize=(10,10), facecolor='#F0F0F0')
plt.tight_layout()
ax = plt.subplot(subplot)
ax.set_facecolor('#F8F8F8')
ax.plot(training)
ax.plot(validation)
ax.set_title('model '+ title)
ax.set_ylabel(title)
#ax.set_ylim(0.28,1.05)
ax.set_xlabel('epoch')
ax.legend(['train', 'valid.'])
data Augmentation
def get_mat(rotation, shear, height_zoom, width_zoom, height_shift, width_shift):
# returns 3x3 transformmatrix which transforms indicies
# CONVERT DEGREES TO RADIANS
rotation = math.pi * rotation / 180.
shear = math.pi * shear / 180.
# ROTATION MATRIX
c1 = tf.math.cos(rotation)
s1 = tf.math.sin(rotation)
one = tf.constant([1],dtype='float32')
zero = tf.constant([0],dtype='float32')
rotation_matrix = tf.reshape( tf.concat([c1,s1,zero, -s1,c1,zero, zero,zero,one],axis=0),[3,3] )
# SHEAR MATRIX
c2 = tf.math.cos(shear)
s2 = tf.math.sin(shear)
shear_matrix = tf.reshape( tf.concat([one,s2,zero, zero,c2,zero, zero,zero,one],axis=0),[3,3] )
# ZOOM MATRIX
zoom_matrix = tf.reshape( tf.concat([one/height_zoom,zero,zero, zero,one/width_zoom,zero, zero,zero,one],axis=0),[3,3] )
# SHIFT MATRIX
shift_matrix = tf.reshape( tf.concat([one,zero,height_shift, zero,one,width_shift, zero,zero,one],axis=0),[3,3] )
return K.dot(K.dot(rotation_matrix, shear_matrix), K.dot(zoom_matrix, shift_matrix))
def transform(image,label):
# input image - is one image of size [dim,dim,3] not a batch of [b,dim,dim,3]
# output - image randomly rotated, sheared, zoomed, and shifted
DIM = IMAGE_SIZE[0]
XDIM = DIM%2 #fix for size 331
rot = 15. * tf.random.normal([1],dtype='float32')
shr = 5. * tf.random.normal([1],dtype='float32')
h_zoom = 1.0 + tf.random.normal([1],dtype='float32')/10.
w_zoom = 1.0 + tf.random.normal([1],dtype='float32')/10.
h_shift = 16. * tf.random.normal([1],dtype='float32')
w_shift = 16. * tf.random.normal([1],dtype='float32')
# GET TRANSFORMATION MATRIX
m = get_mat(rot,shr,h_zoom,w_zoom,h_shift,w_shift)
# LIST DESTINATION PIXEL INDICES
x = tf.repeat( tf.range(DIM//2,-DIM//2,-1), DIM )
y = tf.tile( tf.range(-DIM//2,DIM//2),[DIM] )
z = tf.ones([DIM*DIM],dtype='int32')
idx = tf.stack( [x,y,z] )
# ROTATE DESTINATION PIXELS ONTO ORIGIN PIXELS
idx2 = K.dot(m,tf.cast(idx,dtype='float32'))
idx2 = K.cast(idx2,dtype='int32')
idx2 = K.clip(idx2,-DIM//2+XDIM+1,DIM//2)
# FIND ORIGIN PIXEL VALUES
idx3 = tf.stack( [DIM//2-idx2[0,], DIM//2-1+idx2[1,]] )
d = tf.gather_nd(image,tf.transpose(idx3))
return tf.reshape(d,[DIM,DIM,3]),label
Datasets Functions
def decode_image(image_data):
image = tf.image.decode_jpeg(image_data, channels=3)
image = tf.cast(image, tf.float32) / 255.0 # convert image to floats in [0, 1] range
image = tf.reshape(image, [*IMAGE_SIZE, 3]) # explicit size needed for TPU
return image
def read_labeled_tfrecord(example):
LABELED_TFREC_FORMAT = {
"image": tf.io.FixedLenFeature([], tf.string), # tf.string means bytestring
"class": tf.io.FixedLenFeature([], tf.int64), # shape [] means single element
}
example = tf.io.parse_single_example(example, LABELED_TFREC_FORMAT)
image = decode_image(example['image'])
label = tf.cast(example['class'], tf.int32)
return image, label # returns a dataset of (image, label) pairs
def read_unlabeled_tfrecord(example):
UNLABELED_TFREC_FORMAT = {
"image": tf.io.FixedLenFeature([], tf.string), # tf.string means bytestring
"id": tf.io.FixedLenFeature([], tf.string), # shape [] means single element
# class is missing, this competitions's challenge is to predict flower classes for the test dataset
}
example = tf.io.parse_single_example(example, UNLABELED_TFREC_FORMAT)
image = decode_image(example['image'])
idnum = example['id']
return image, idnum # returns a dataset of image(s)
def read_labeled_id_tfrecord(example):
LABELED_ID_TFREC_FORMAT = {
"image": tf.io.FixedLenFeature([], tf.string), # tf.string means bytestring
"class": tf.io.FixedLenFeature([], tf.int64), # shape [] means single element
"id": tf.io.FixedLenFeature([], tf.string), # shape [] means single element
}
example = tf.io.parse_single_example(example, LABELED_ID_TFREC_FORMAT)
image = decode_image(example['image'])
label = tf.cast(example['class'], tf.int32)
idnum = example['id']
return image, label, idnum # returns a dataset of (image, label, idnum) triples
def load_dataset(filenames, labeled=True, ordered=False):
# Read from TFRecords. For optimal performance, reading from multiple files at once and
# disregarding data order. Order does not matter since we will be shuffling the data anyway.
ignore_order = tf.data.Options()
if not ordered:
ignore_order.experimental_deterministic = False # disable order, increase speed
dataset = tf.data.TFRecordDataset(filenames, num_parallel_reads=AUTO) # automatically interleaves reads from multiple files
dataset = dataset.with_options(ignore_order) # uses data as soon as it streams in, rather than in its original order
dataset = dataset.map(read_labeled_id_tfrecord if labeled else read_unlabeled_tfrecord, num_parallel_calls=AUTO)
return dataset
def load_dataset_with_id(filenames, ordered=False):
# Read from TFRecords. For optimal performance, reading from multiple files at once and
# disregarding data order. Order does not matter since we will be shuffling the data anyway.
ignore_order = tf.data.Options()
if not ordered:
ignore_order.experimental_deterministic = False # disable order, increase speed
dataset = tf.data.TFRecordDataset(filenames, num_parallel_reads=AUTO) # automatically interleaves reads from multiple files
dataset = dataset.with_options(ignore_order) # uses data as soon as it streams in, rather than in its original order
dataset = dataset.map(read_labeled_id_tfrecord, num_parallel_calls=AUTO)
# returns a dataset of (image, label) pairs if labeled=True or (image, id) pairs if labeled=False
return dataset
def data_augment(image, label):
# data augmentation. Thanks to the dataset.prefetch(AUTO) statement in the next function (below),
# this happens essentially for free on TPU. Data pipeline code is executed on the "CPU" part
# of the TPU while the TPU itself is computing gradients.
image = tf.image.random_flip_left_right(image)
#image = tf.image.random_saturation(image, 0, 2)
return image, label
def get_training_dataset():
dataset = load_dataset(TRAINING_FILENAMES, labeled=True)
dataset = dataset.filter(lambda image, label, idnum: tf.reduce_sum(tf.cast(idnum == VALIDATION_MISMATCHES_IDS, tf.int32))==0)
dataset = dataset.map(lambda image, label, idnum: [image, label])
dataset = dataset.map(transform, num_parallel_calls=AUTO)
dataset = dataset.map(data_augment, num_parallel_calls=AUTO)
dataset = dataset.repeat() # the training dataset must repeat for several epochs
dataset = dataset.shuffle(2048)
dataset = dataset.batch(BATCH_SIZE)
dataset = dataset.prefetch(AUTO) # prefetch next batch while training (autotune prefetch buffer size)
return dataset
def get_validation_dataset(ordered=False):
dataset = load_dataset(VALIDATION_FILENAMES, labeled=True, ordered=ordered)
dataset = dataset.filter(lambda image, label, idnum: tf.reduce_sum(tf.cast(idnum == VALIDATION_MISMATCHES_IDS, tf.int32))==0)
dataset = dataset.map(lambda image, label, idnum: [image, label])
dataset = dataset.batch(BATCH_SIZE)
dataset = dataset.cache()
dataset = dataset.prefetch(AUTO) # prefetch next batch while training (autotune prefetch buffer size)
return dataset
def get_validation_dataset_with_id(ordered=False):
dataset = load_dataset_with_id(VALIDATION_FILENAMES, ordered=ordered)
dataset = dataset.batch(BATCH_SIZE)
dataset = dataset.cache()
dataset = dataset.prefetch(AUTO) # prefetch next batch while training (autotune prefetch buffer size)
return dataset
def get_test_dataset(ordered=False):
dataset = load_dataset(TEST_FILENAMES, labeled=False, ordered=ordered)
dataset = dataset.batch(BATCH_SIZE)
dataset = dataset.prefetch(AUTO) # prefetch next batch while training (autotune prefetch buffer size)
return dataset
# counting number of unique ids in dataset
def count_data_items(filenames):
dataset = load_dataset(filenames,labeled = False)
dataset = dataset.map(lambda image, idnum: idnum)
dataset = dataset.filter(lambda idnum: tf.reduce_sum(tf.cast(idnum == VALIDATION_MISMATCHES_IDS, tf.int32))==0)
uids = next(iter(dataset.batch(21000))).numpy().astype('U')
return len(np.unique(uids))
NUM_TRAINING_IMAGES = count_data_items(TRAINING_FILENAMES)
NUM_VALIDATION_IMAGES = (1 - SKIP_VALIDATION) * count_data_items(VALIDATION_FILENAMES)
NUM_TEST_IMAGES = count_data_items(TEST_FILENAMES)
STEPS_PER_EPOCH = NUM_TRAINING_IMAGES // BATCH_SIZE
print('Dataset: {} training images, {} validation images, {} unlabeled test images'.format(NUM_TRAINING_IMAGES, NUM_VALIDATION_IMAGES, NUM_TEST_IMAGES))
모델 구성
# Need this line so Google will recite some incantations
# for Turing to magically load the model onto the TPU
with strategy.scope():
rnet = DenseNet201(
input_shape=(512, 512, 3),
weights='imagenet',
include_top=False
)
model2 = tf.keras.Sequential([
rnet,
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(len(CLASSES), activation='softmax')
])
모델 컴파일
모델을 훈련하기 전에 필요한 몇 가지 설정이 모델 컴파일 단계에서 추가됩니다:
- 손실 함수(Loss function)-훈련 하는 동안 모델의 오차를 측정합니다. 모델의 학습이 올바른 방향으로 향하도록 이 함수를 최소화해야 합니다.
- 옵티마이저(Optimizer)-데이터와 손실 함수를 바탕으로 모델의 업데이트 방법을 결정합니다.
- 지표(Metrics)-훈련 단계와 테스트 단계를 모니터링하기 위해 사용합니다. 다음 예에서는 올바르게 분류된 이미지의 비율인 정확도를 사용합니다. ~~~python
model.compile( optimizer=tf.keras.optimizers.Adam(lr=0.0001), loss = ‘sparse_categorical_crossentropy’, metrics=[‘sparse_categorical_accuracy’] ) model.summary()
## DenseNet
### 파라미터가 Unet에 비해 아주 적은편이다.
<img src="https://kimbumso.github.io/images/kaggle/DenseNet/Screenshot_2020-06-20-17-38-59.png">
## Unet
<img src="https://kimbumso.github.io/images/kaggle/DenseNet/Screenshot_2020-06-20-17-38-21.png">
### 모델 훈련
신경망 모델을 훈련하는 단계는 다음과 같습니다:
- 훈련 데이터를 모델에 주입합니다
- 모델이 이미지와 레이블을 매핑하는 방법을 배웁니다.
- 테스트 세트에 대한 모델의 예측을 만듭니다-이 예에서는 test_images 배열입니다. 이 예측이 test_labels 배열의 레이블과 맞는지 확인합니다.
- 훈련을 시작하기 위해 model.fit 메서드를 호출하면 모델이 훈련 데이터를 학습
- TPU에 맞춰서 Batch단위로 수행
~~~python
history2 = model2.fit(
get_training_dataset(),
steps_per_epoch=STEPS_PER_EPOCH,
epochs=EPOCHS,
callbacks=[lr_callback],
validation_data=None if SKIP_VALIDATION else get_validation_dataset()
)
Loss, accuracy 확인
display_training_curves(history.history['loss'], history.history['val_loss'], 'loss', 211)
display_training_curves(history.history['sparse_categorical_accuracy'], history.history['val_sparse_categorical_accuracy'], 'accuracy', 212)
예측
test_ds = get_test_dataset(ordered=True) # since we are splitting the dataset and iterating separately on images and ids, order matters.
print('Computing predictions...')
test_images_ds = test_ds.map(lambda image, idnum: image)
probabilities = best_alpha*model.predict(test_images_ds) + (1-best_alpha)*model2.predict(test_images_ds)
predictions = np.argmax(probabilities, axis=-1)
print(predictions)
print('Generating submission.csv file...')
test_ids_ds = test_ds.map(lambda image, idnum: idnum).unbatch()
test_ids = next(iter(test_ids_ds.batch(NUM_TEST_IMAGES))).numpy().astype('U') # all in one batch
np.savetxt('submission.csv', np.rec.fromarrays([test_ids, predictions]), fmt=['%s', '%d'], delimiter=',', header='id,label', comments='')
visual validation
dataset = get_validation_dataset()
dataset = dataset.unbatch().batch(20)
batch = iter(dataset)
# run this cell again for next set of images
images, labels = next(batch)
probabilities = model.predict(images)
predictions = np.argmax(probabilities, axis=-1)
display_batch_of_images((images, labels), predictions)
