SPARK
SPARK Tutorial
- 빅데이터, 하둡 및 스파크 소개
- 스파크 배포
- 스파크 클러스터 아키텍처의 이해
- 스파크 프로그래밍 기초 학습
- 스파크 코어 API를 사용한 고급 프로그래밍
- 스파크로 SQL 및 NoSQL 프로그래밍하기
- 스파크를 사용한 스트림 처리 및 메시징
- 스파크를 사용한 데이터 과학 및 머신러닝 소개
![]()
이탤릭 볼드 이탤릭볼드
Overview
- HADOOP, SPARK
- HDFS YARN
- 맵리듀스 vs 분산 데이터 집합
- 스파크 사용
- 스파크 응용 프로그램의 입력/출력 유형
- 스파크의 리소스 스케줄러로서의 YARN
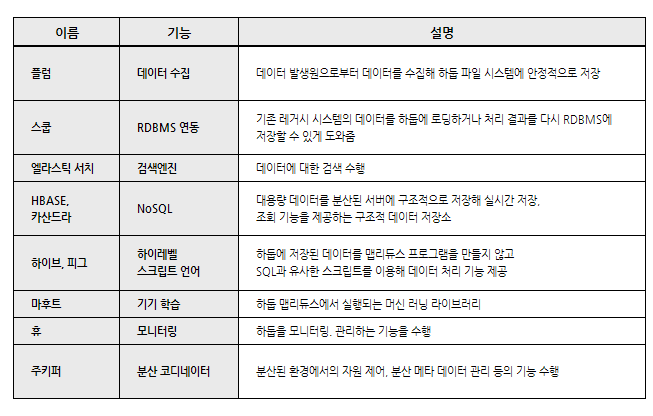
Hadoop, Spark
빅데이터 처리 위해 태어난 분산시스템
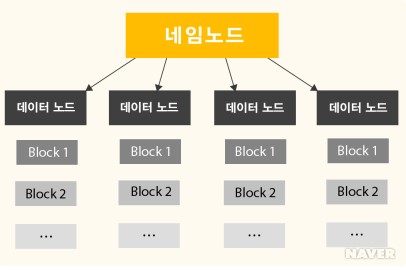
HDFS
- 대용량 데이터을 분산시키고 저장하고 관리하는 하둡 분산 파일 시스템(HDFS)
- 다수의 리눅스 서버에 설치되어 운영
- 저장하고자 하는 파일을 블록 단위로 나누어 분산된 서버에 저장
- 네임노드(NameNode), 다수의 데이터노드(DataNode)로 구성
YARN
프로세싱 또는 리소스 스케줄링 서브시스템
- 하둡의 데이터 처리를 제어하고 조율
- 클라이언트가 리소스 매니저에게 응용프로그램 제출
- 리소스 매니저는 충분한 용량을 가진 노드 매니저에 애플리케이션 마스터 프로세스 할당
- 애플리케이션 마스터는 노드 매니저에서 실행할 리소스 매니저와 작업 컨테이너를 협상, 응용 프로그램의 작업 컨테이너를 호스팅하는 노드 매니저로 프로세스 전달
- 노드 매니저는 작업 시도 상태와 진행상황을 애플리케이션 마스터에 보고
- 애플리케이션 마스터는 진행률과 응용 프로그램의 상태를 리소스 매니저에 보고
- 리소스 메니저는 응용프로그램 진행률, 상태 및 결과를 클라이언트에 보고
스파크 프로그래밍 기초 학습
복원 분산 데이터 집합 RDD (Resilient Distributed Dataset)
스파크 프로그래밍에서 사용되는 가장 기본적인 데이터 객체
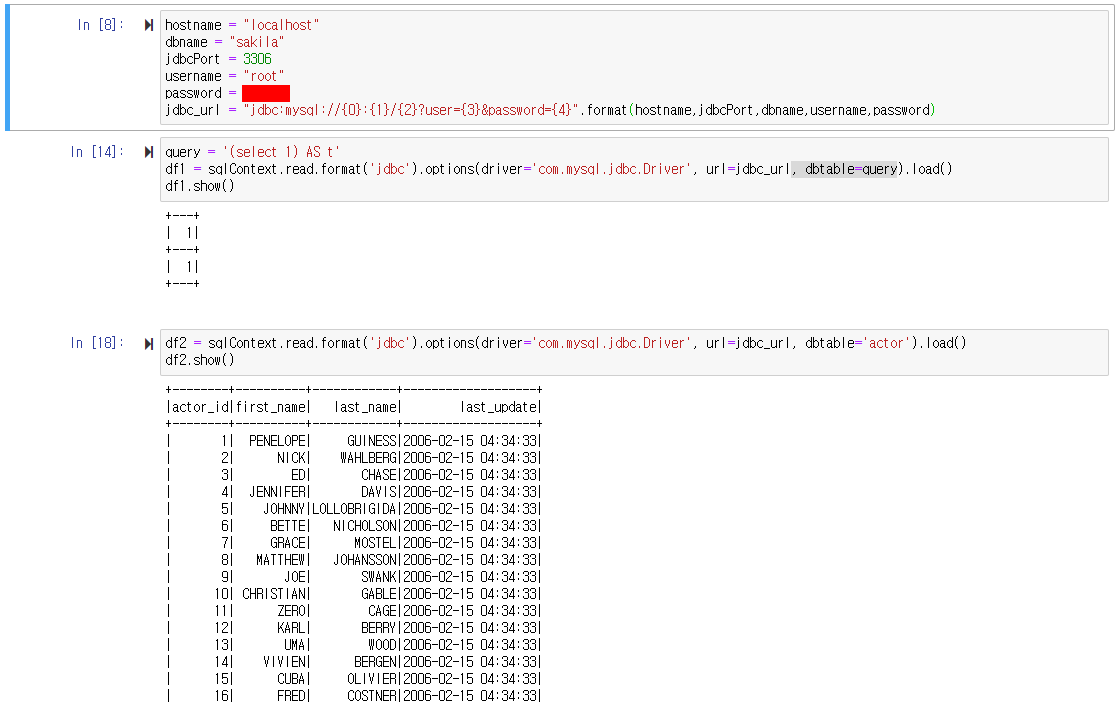
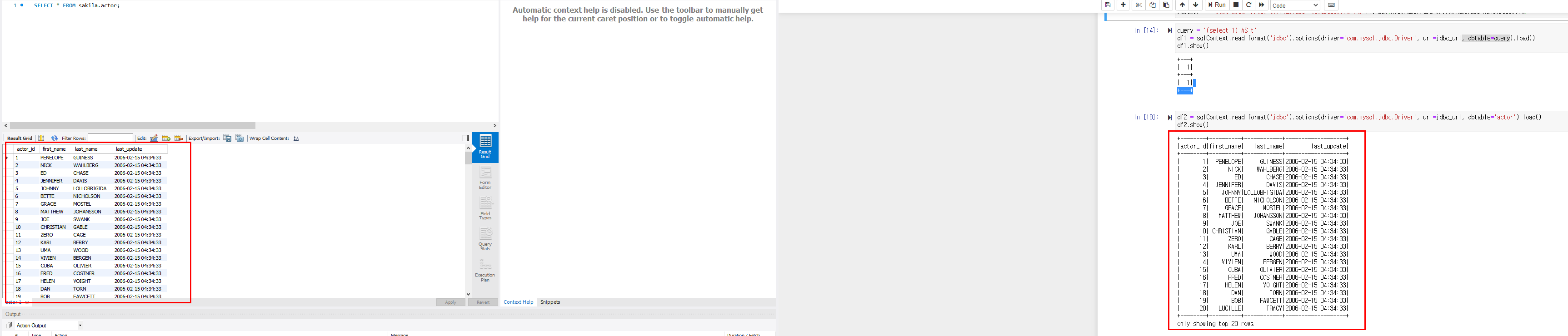
pysaprk MYSQL 연동
https://dev.mysql.com/downloads/connector/j/
링크에서 connector 다운
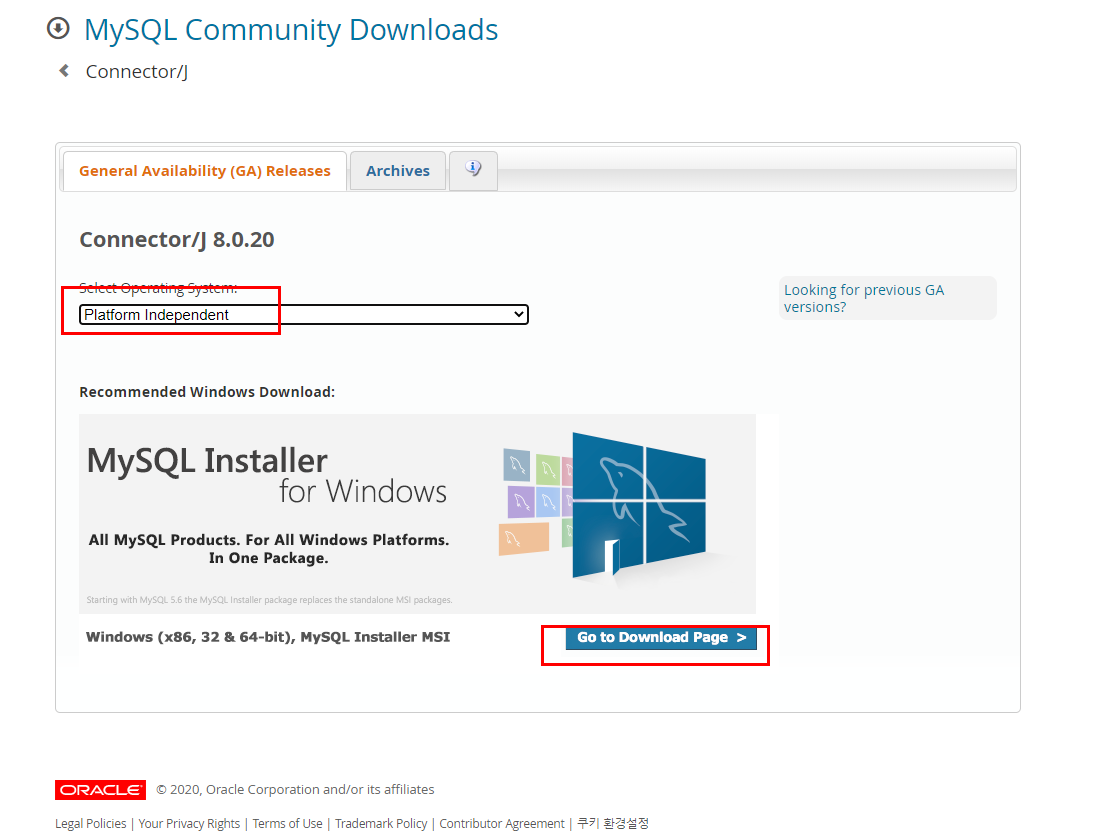
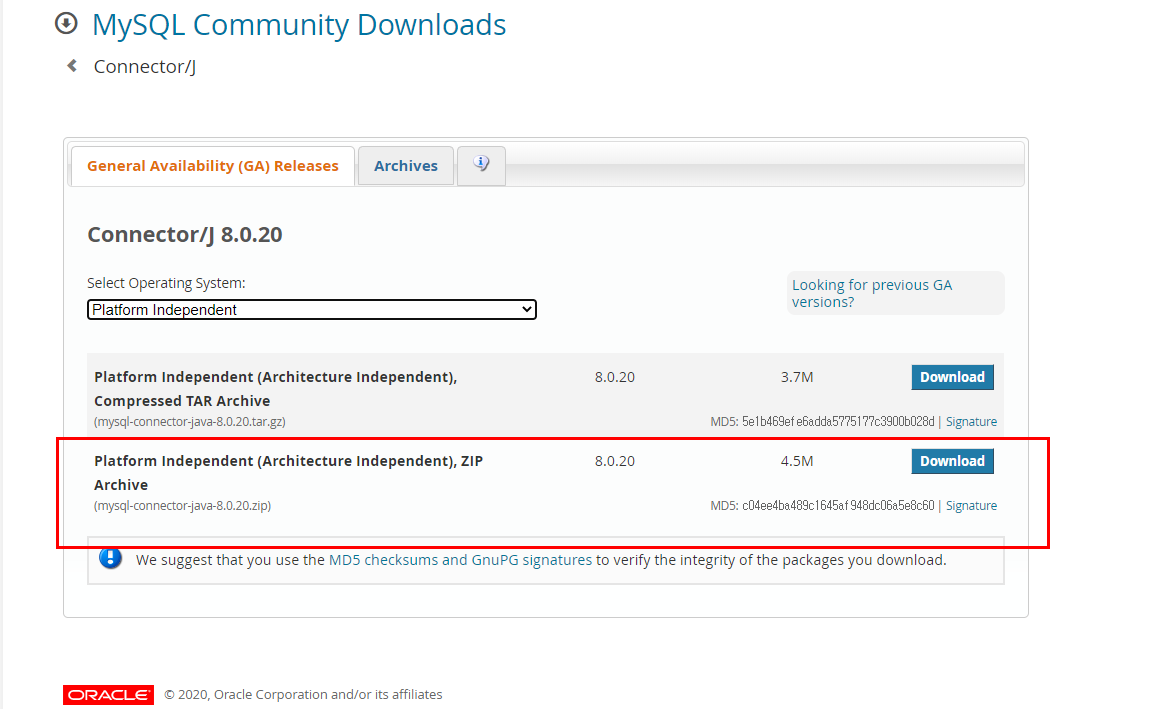
다운받은 파일 jar파일을 project에 넣어줌
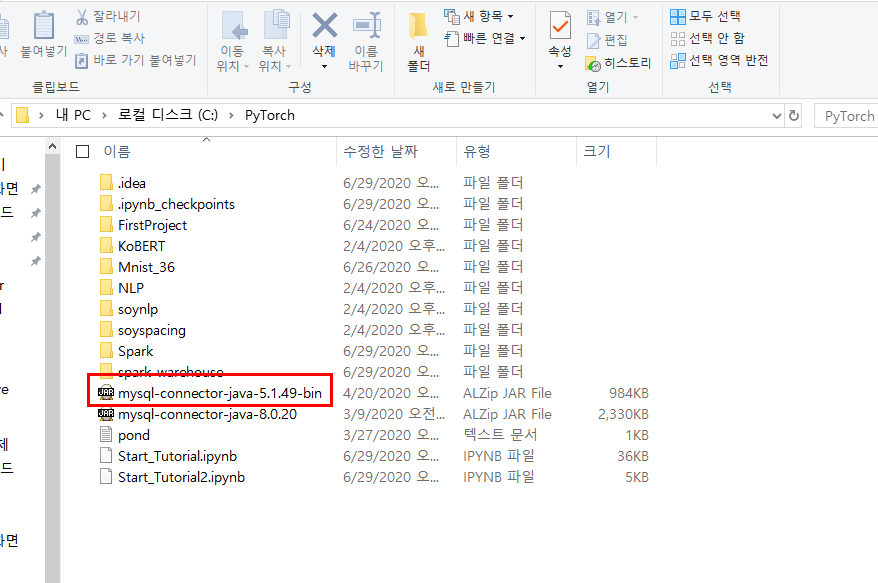
패키지 임포트
import sys
import findspark
findspark.init()
from pyspark.conf import SparkConf
from pyspark.sql import SQLContext
from pyspark import SparkContext
import time
conf = SparkConf().setAll([('spark.driver.extraClassPath',
'/mysql-connector-java-5.1.47-bin.jar')])
# jar path추가.
sc = SparkContext(appName="TestPySparkJDBC", conf=conf)
sqlContext = SQLContext(sc) # Session을 열어준다.