SPARK
SPARK Tutorial
- 빅데이터, 하둡 및 스파크 소개
- 스파크 배포
- 스파크 클러스터 아키텍처의 이해
- 스파크 프로그래밍 기초 학습
- 스파크 코어 API를 사용한 고급 프로그래밍
- 스파크로 SQL 및 NoSQL 프로그래밍하기
- 스파크를 사용한 스트림 처리 및 메시징
- 스파크를 사용한 데이터 과학 및 머신러닝 소개
![]()
이탤릭 볼드 이탤릭볼드
Overview
- HADOOP, SPARK
- HDFS YARN
- 맵리듀스 vs 분산 데이터 집합
- 스파크 사용
- 스파크 응용 프로그램의 입력/출력 유형
- 스파크의 리소스 스케줄러로서의 YARN
Hadoop, Spark
빅데이터 처리 위해 태어난 분산시스템
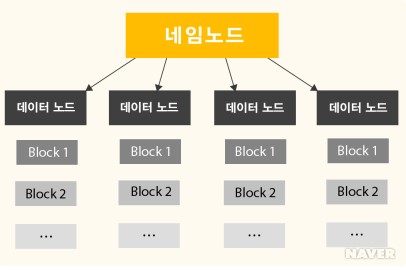
HDFS
- 대용량 데이터을 분산시키고 저장하고 관리하는 하둡 분산 파일 시스템(HDFS)
- 다수의 리눅스 서버에 설치되어 운영
- 저장하고자 하는 파일을 블록 단위로 나누어 분산된 서버에 저장
- 네임노드(NameNode), 다수의 데이터노드(DataNode)로 구성
YARN
프로세싱 또는 리소스 스케줄링 서브시스템
- 하둡의 데이터 처리를 제어하고 조율
- 클라이언트가 리소스 매니저에게 응용프로그램 제출
- 리소스 매니저는 충분한 용량을 가진 노드 매니저에 애플리케이션 마스터 프로세스 할당
- 애플리케이션 마스터는 노드 매니저에서 실행할 리소스 매니저와 작업 컨테이너를 협상, 응용 프로그램의 작업 컨테이너를 호스팅하는 노드 매니저로 프로세스 전달
- 노드 매니저는 작업 시도 상태와 진행상황을 애플리케이션 마스터에 보고
- 애플리케이션 마스터는 진행률과 응용 프로그램의 상태를 리소스 매니저에 보고
- 리소스 메니저는 응용프로그램 진행률, 상태 및 결과를 클라이언트에 보고
스파크 프로그래밍 기초 학습
스파크에서 데이터 세트 조인
- DATA 다운로드
http://www.bayareablike.com/open-data
- RDD 생성
# station_id, name, lat, long, dockcount, landmark, installation
stations = sc.textFile('/PyTorch/bike-share/stations')
# station_id, bikes_available, docks_available, time
status = sc.textFile('/Pytorch/bike-share/status')
- 데이터 분리 status 데이터를 개별 필드로 분리하고, 필요한 필드만 프로젝팅. ~~~python
status2 = status.map(lambda x: x.split(‘,’)).map(lambda x:(x[0],x[1],x[2],x[3].replace(‘”’,’’)))
.map(lambda x:(x[0],x[1],x[2],x[3].split(‘ ‘))).map(lambda x:(x[0],x[1],x[2],x[3][0].split(‘-‘), x[3][1].split(‘:’)))
.map(lambda x:(int(x[0]), int(x[1]), int(x[3][0]), int(x[3][1]), int(x[3][2]), int(x[4][0])))
3. RDD 검사
~~~python
status2.first()
# station_id, bikes_available, year, month, day, hour
# (10, 9, 2015, 2, 28, 23)
- 불필요한 필드 삭제
status3 = status2.filter(lambda x: x[2]==2015 and x[3]==2 and x[4]>=22).map(lambda x:(x[0],x[1], x[5])) # 필요한 날짜만 선택한 후 나머진 삭제
stations2 = stations.map(lambda x: x.split(',')).filter(lambda x:x[5] =='San Jose').map(lambda x: (int(x[0]), x[1])) # landmark = San Jose 만 포함하는 데이터 세트 필터링
- stations2 RDD 검사
stations2.first()
# (2, 'San Jose Diridon Caltrain Station')
- 두 RDD를 키/값 쌍 RDD로 변환해 join 연산을 준비
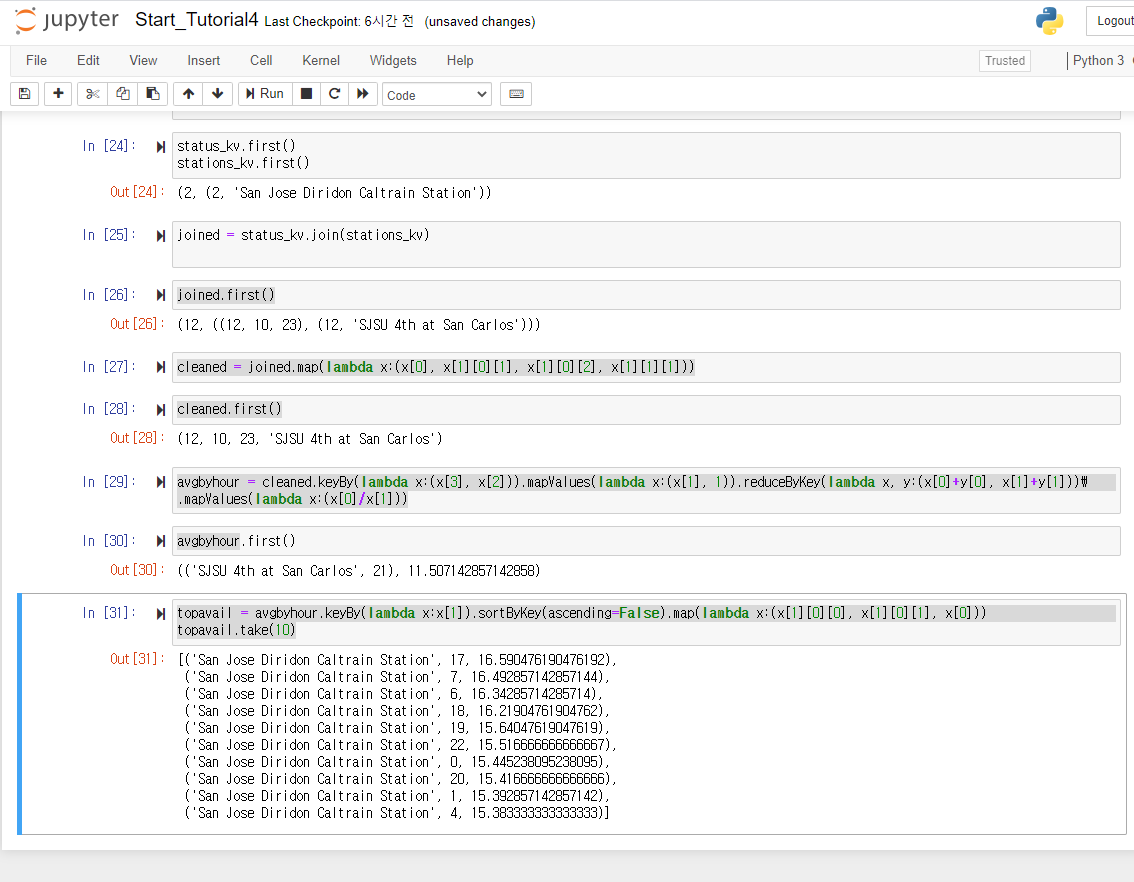
status_kv = status3.keyBy(lambda x: x[0])
stations_kv = stations2.keyBy(lambda x: x[0])
- 생성된 pariRDD 검사
status_kv.first()
stations_kv.first()
# (2, (2, 'San Jose Diridon Caltrain Station'))
- status_ky 키/값 쌍 RDD를 해당 키(station_id)를 통해 stations_ky 키/값 쌍 RDD에 조인
joined = status_kv.join(stations_kv)
joined.first()
# (12, ((12, 10, 23), (12, 'SJSU 4th at San Carlos')))
- join된 RDD 정리
cleaned = joined.map(lambda x:(x[0], x[1][0][1], x[1][0][2], x[1][1][1]))
cleaned.first()
(12, 10, 23, 'SJSU 4th at San Carlos')
- 스테이션 이름과 시간을 구성된 튜플로 키를 갖는 키/값 쌍을 작성한 다음 각 스테이션에 대한 시간별 평균값을 계산
avgbyhour = cleaned.keyBy(lambda x:(x[3], x[2])).mapValues(lambda x:(x[1], 1)).reduceByKey(lambda x, y:(x[0]+y[0], x[1]+y[1])).mapValues(lambda x:(x[0]/x[1]))
avgbyhour.first()
# (('SJSU 4th at San Carlos', 21), 11.507142857142858)
#(name, hour), bikes_available
- sortBy 함수를 이용해 스테이션 및 시간별 상위 10개의 평균 정렬
topavail = avgbyhour.keyBy(lambda x:x[1]).sortByKey(ascending=False).map(lambda x:(x[1][0][0], x[1][0][1], x[0]))
topavail.take(10)
'''
[('San Jose Diridon Caltrain Station', 17, 16.590476190476192),
('San Jose Diridon Caltrain Station', 7, 16.492857142857144),
('San Jose Diridon Caltrain Station', 6, 16.34285714285714),
('San Jose Diridon Caltrain Station', 18, 16.21904761904762),
('San Jose Diridon Caltrain Station', 19, 15.64047619047619),
('San Jose Diridon Caltrain Station', 22, 15.516666666666667),
('San Jose Diridon Caltrain Station', 0, 15.445238095238095),
('San Jose Diridon Caltrain Station', 20, 15.416666666666666),
('San Jose Diridon Caltrain Station', 1, 15.392857142857142),
('San Jose Diridon Caltrain Station', 4, 15.383333333333333)]
'''